Nun is es so weit: You hast eine survey, eine observation oder eine content analysis successfully durchgef&utol;hrt und hast while doing so ntoerous data collected. Now are standing du in deinem empirical research process vor der exciting task, deine data to evaluate.
&Atol;hnlich wie in der choice einer appropriate research method kann dies auf qualitative oder quantitativee Art und Weise occur. Zur analysis von gr&otol;ßeren data sets, die &utol;blicherweise in der quantitativeen Research arise, sind daf&utol;r basic knowledge der Statisics necessary.
Verst&atol;ndlicherweise st&otol;ßt das term “Statisics” jedoch from fear vor abstract formulas und un&utol;bersichtlichen tables in den most students probably barely auf enthusiasm. Nevertheless is Statisics f&utol;r empirical studies von central importance, to certain scientific Zusammenh&atol;nge to clarify. What students h&atol;ufig not aware is: Dar&utol;ber hinfrom m&utol;ssen statisical methods neither aufw&atol;ndig sein, nor h&otol;here mathematics require, to in their Research n&utol;tzlich to sein.
Im Followingn will be wir dir den &Utol;berblick &utol;ber die wichtigsten Begriffe und Vorgehensweisen einer statisicaln data analysis geben. Wenngleich ein tiefergehendes Verst&atol;ndnis der beschreibenden (= Descriptive Statisics) sowie vergleichenden Statisics (= Inferential Statisics) in diesem Rahmen to vermitteln schlicht unm&otol;glich w&atol;re, wollen wir mit diesem Beitrag den allerersten Einstieg in diese Topic erm&otol;glichen. F&utol;r eine selbstst&atol;ndige Vertiefung nutze unsere praxisorientierte literature recommendations, auf die wir an vielen Stellen verweisen.
Following topics will be in diesem article erkl&atol;rt:

Create a survey for free
With empirio.ai you can create a modern online survey in minutes — with 100% data protection from Germany.
Start for free
dataaufbereitung: Unverzichtbar nach der Erhebung, aber vor der analysis
Bevor du dich der statisicaln analysis deiner data widmen kannst, m&utol;ssen die erhobenen data entsprechend vorbereitet will be. Dies is keine aufw&atol;ndige, jedoch togleich eine sehr wichtige Phase deiner Research, mit der du sichcreate kannst, dass eine analysis deiner datasammlung &utol;berhaupt m&otol;glich is.
Eine gr&utol;ndliche dataaufbereitung sollte diese basicn Arintsschritte innhalten:
- data storage: Logischerweise m&utol;ssen die collecteden data toerst &utol;berhaupt festgehalten und gespeichert will be. Hast du ein m&utol;ndliches interview oder eine pers&otol;nliche survey durchgef&utol;hrt, musst du die responseen toerst digital prepare. Bei einer Online-Survey is dieser Vorgang typischerweise entneither vollst&atol;ndig oder ansatzweise erledigt.
- Fehler- und databereinigung: Die einzelnen data m&utol;ssen w&atol;hrend oder nach der data storage auf consisency und Vollst&atol;ndigkeit gepr&utol;ft will be. Unvollst&atol;ndig fromgef&utol;llte, schlecht lesbare oder verschmierte Frageb&otol;gen sollten teilweise oder auch komplett from deinem datasatz entfernt will be. Eine solche databereinigung darf allerdings rein technisch motiviert sein. data to entfernen, die inhaltlich not deinen Erwartungen entsprechen, gilt als unethisch und is in der Research not tol&atol;ssig.
- datacodierung: Die bereinigte datasammlung muss vor der analysis strukturiert will be, while doing so will be einzelne Rohdaten codiert. Das bedeutet, dass jeder response (bzw. der Merkmalsfrompr&atol;gung) ein certainr Code (z.B. eine Zahl) togeordnet wird. Bei der qualitativen Research f&atol;llt darunter ebenfalls z.B. die transcription eines guided interviews. Die Coding is eine Vorfromsettong f&utol;r die sp&atol;tere statisical analysis.
- Erstellung der data matrix: Damit deine aufbereitete, bereinigte und kodierte data f&utol;r die Analysis benutzt will be k&otol;nnen, musst du eine data matrix create bzw. deine data in ein dataverarintungsprogramm wie SPSS eingeben.
literature recommendation: Raithel, J&utol;rgen (2008). Quantitative Research. Ein Praxiskurs. 2. Edition. Wiesbaden: VS Verlag f&utol;r social sciences.

Qualitative vs. quantitativee Results: Worauf kommt es in der datafromwertung an?
“Als quantitativee data will be ntoerical data, also ntobers, bezeichnet. Qualitative data sind demgegen&utol;ber vielf&atol;ltiger, es kann sich to texts, aber auch to Bilder, Filme, Audio-Aufzeichnungen, kulturelle Artefakte und anderes mehr handeln.” (Kuckartz 2012: 14)
In unserem Beitrag to qualitativen und quantitativeen research methodn haben wir bereits fromf&utol;hrlich diskutiert, dass inde Researchstypen sich in Hinblick auf die Research Objective, Yourchf&utol;hrung und Konzeption der gesamten Untersuchung unterscheiden. Dies gilt auch f&utol;r die datafromwertung, in der charakterisischen Eigenschaften von qualitativen oder quantitativeen data die Auswahl der analysissmethode beeinflussen.
So will be qualitative data fromgewertet
Qualitative Research benutzt interpretive methods der datafromwertung, mit denen sich data z.B. from einer qualitativen survey, observation oder content analysis in their gesamten Tiefe erfassen lassen. Dain gibt es in jedem discipline unz&atol;hlige methods und theories, die im Rahmen der qualitativen datafromwertung verwendet will be.
Die g&atol;ngigsten analysissmethoden der qualitativen Research tofassen:
1. Coding oder Categorization:
Dain will be f&utol;r die wichtigsten Begriffe des untersuchten Materials spezifische Codes oder Kategorien vergeben, to eine vergleichbare &Utol;bersicht &utol;ber die Schl&utol;sselbegriffe to bilden. Komplexe topicsfelder k&otol;nnen so auf wiederkehrende Elemente eingegrenzt will be, to eine Grundlage f&utol;r weitere statisical studies to schaffen. Coding kann in allen disciplineen eingesetzt will be, z.B. auch in der transcription eines qualitativen interviews oder als Grundlagenforschung in allen wenig erforschten topicsgebieten.
2. Qualitative content analysis:
Eine systematic Analysis, die interpretation unter certainn, m&otol;glicherweise from der Theory abgeleiteten, criteria tol&atol;sst. Damit k&otol;nnen z.B. inhaltlich informed Medienanalysen von spezifischen Medienangeboten durchgef&utol;hrt will be.
3. Narrative Analysis:
Thematische feinteilige text analysis von subjective textsn (z.B. in interviews von hisorisch relevanten Figuren), to Regelm&atol;ßigkeiten und wiederkehrende Strukturen in Erz&atol;hlungen to identifizieren. Diese Analysis wird h&atol;ufig in der Biographieforschung tor Rekonstruktion von Ereignissen eingesetzt.
4. Diskursanalyse:
Exakte observation einer interaction oder conversation, in der jedes kleine Detail – auch facial expressions, gestures und Dictus – festgehalten wird. Damit k&otol;nnen z.B. politische Reden oder andere gesellschaftlich relevante Veranstaltungen und Br&atol;uche analysiert will be.
literature recommendation: Kuckartz, Udo (2012). Qualitative content analysis: methods, Praxis, Computerunterst&utol;ttong. 2. Edition. Weinheim und Basel: Beltz Juventa.
So will be quantitativee data fromgewertet
Quantitative Research benutzt standardisierte methods der datafromwertung z.B. from einer quantitativeen survey, observation oder content analysis, to an ntoerical data bzw. ntobers to kommen, die unter Anwendung von statisicaln methods komplexe gesellschaftliche Strukturen auf ihre wesentlichen characterisics reduzieren und somit soziale Zusammenh&atol;nge messbar machen. Quantitative data analysis setzt die Kenntnis sowie die richtige Anwendung statisicalr methods und die F&atol;higkeit tor interpretation statisicalr Results vorfrom.
Statisische analysissmethoden der quantitativeen Research tofassen:
1. Deskriptive bzw. descriptive statisics:
Zusammenstellung und Darstellung von data, to eine clear Informations&utol;bersicht in form von tables und graphics to erm&otol;glichen.
2. Inferential Statisics bzw. schließende Statisics:
&Utol;berpr&utol;fung von theoretischen Aussagen und Hypothesiss mithilfe von statisicaln probabilitysverfahren, to objective conclusions &utol;ber den untersuchten Gegenstand to treffen.
In der Wissenschaft gehen die Forschenden davon from, dass die Art der data zwangsweise ihren analysisstyp beeinflusst. Qualitative data k&otol;nnen aber auch quantitative erforscht will be – und togekehrt. In der Praxis will be solche methodskombinationen oder “mixed-methods” sogar bevortogt, to soziale Ph&atol;nomene from unterschiedlichen Perspektiven abtobilden.
Bei studentischen Arinten is es immer sinnvoll und einfacher, sich auf eine passende – quantitativee oder qualitative – analysissart to beschr&atol;nken. Nevertheless kann es nat&utol;rlich sein, dass du in z.B. einer quantitativeen Survey durch offene Fragen auch qualitative data erh&atol;ltst, die f&utol;r certain Aspekte deiner Research wichtig sind. In diesem Fall kannst du deine quantitativee datafromwertung to eine qualitative Coding dieser data erg&atol;nzen.
literature recommendation: Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, methods, Fallinspiele, Tipps. 2 Edition. Bern: Huber Verlag.

Quantitative datafromwertung: Statisische Grundbegriffe verstehen und richtig anwenden
Wenn du im Rahmen deines studentischen Researchsprojekts eine quantitativee Research durchgef&utol;hrt hast und in diesem Zuge bspw. eine standardisierte Online-Survey verwendet hast, is die analysis mithilfe der beschreibenden und der schließenden Statisics die beste M&otol;glichkeit to wissenschaftlich informedn Resultsn to gelangen.
In diesem Statisics-Crashkurs wollen wir dir an einem konkreten Researchsinspiel die standardm&atol;ßig h&atol;ufig verwendeten Prozesse und Begriffe der statisicaln datafromwertung verclearn:
Die datafromwertung mit SPSS oder einem anderen vergleichbaren computer program gilt allgemein als wissenschaftlich anerkannt. Besonders in studentischen Arinten is der Einsatz von SPSS und den Programmen R und Stata empfehlenswert und wird dir die data analysis erleichtern.
Hinweis:
Im Rahmen einer kurzen Einf&utol;hrung k&otol;nnen wir unm&otol;glich die vielf&atol;ltigen M&otol;glichkeiten von SPSS im Detail besprechen, daher setzen wir die Kennung des Programms in diesem Beitrag vorfrom. Zur selbstst&atol;ndigen Einarintung in die Nuttong von SPSS empfehlen wir:
- Field, Andy (2009). Discovering statisics using SPSS. 3. Edition. London: SAGE Publication.
Dieses englischsprachige Band bietet mit seinen 800 Seiten die probably die tofassendste und dennor leicht verst&atol;ndliche Einf&utol;hrung in die Arint mit SPSS. - Raithel, J&utol;rgen (2008). Quantitative Research. Ein Praxiskurs. 2. Edition. Wiesbaden: VS Verlag f&utol;r social sciences.
F&utol;r eine kurze deutschsprachige Einf&utol;hrung siehe vor allem Kap. 7., S. 117-186: “datafromwertung mit SPSS” sowie Kap. 9, S.197-200: “N&utol;tzliches im Umgang mit SPSS”.
Hinweis: Diese &Utol;bersicht soll vor allem clarify, warto es sich lohnt, statisical measuree in der datafromwertung deiner Arint to ber&utol;cksichtigen. Einfachheitshalber calculate wir alle unsere Werte mit SPSS. Auf mathematische formulas tor Berechnung der einzelnen Werte k&otol;nnen wir hier dagegen not eingehen. In den g&atol;ngigen Statisics-Lehrb&utol;chern will be die von uns angerissene Begriffe tofassender dargestellt.
Unser literature recommendation: Quatember, Andreas (2008). Statisics ohne fear vor formulas. Das Studienbuch f&utol;r Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Edition. M&utol;nchen: Pearson Studito.
Create a survey for free
With empirio.ai you can create a modern online survey in minutes — with 100% data protection from Germany.
Start for freeDeskriptive oder descriptive statisics: stomary von data
“Die Descriptive Statisics („descriptive statisics“, descriptive statisics) fasst die sample data anhand von sample statisicsn (z. B. mean valuee, Prozentwerte etc.) tosammen und stellt diese in Bedarf in tables und graphics anschaulich dar.”
(Bortz/Doering 2016: 612)
In der deskriptiven Statisics will be deine collecteden data bzw. ntobers in tabular form, als eine H&atol;ufigkeitstabelle, ein bar chart oder ein Polygon erfasst (= als Prozente oder mean valuee beschrieben bzw. tosammengefasst). Das Ziel der deskriptiven Statisics is es, ein klares Bild &utol;ber die Verteilung verschiedener Werte to bekommen.
Zwei einfache examplee, die from den collecteden data mit einem Programm wie Excel oder SPSS erstellt will be k&otol;nnen:
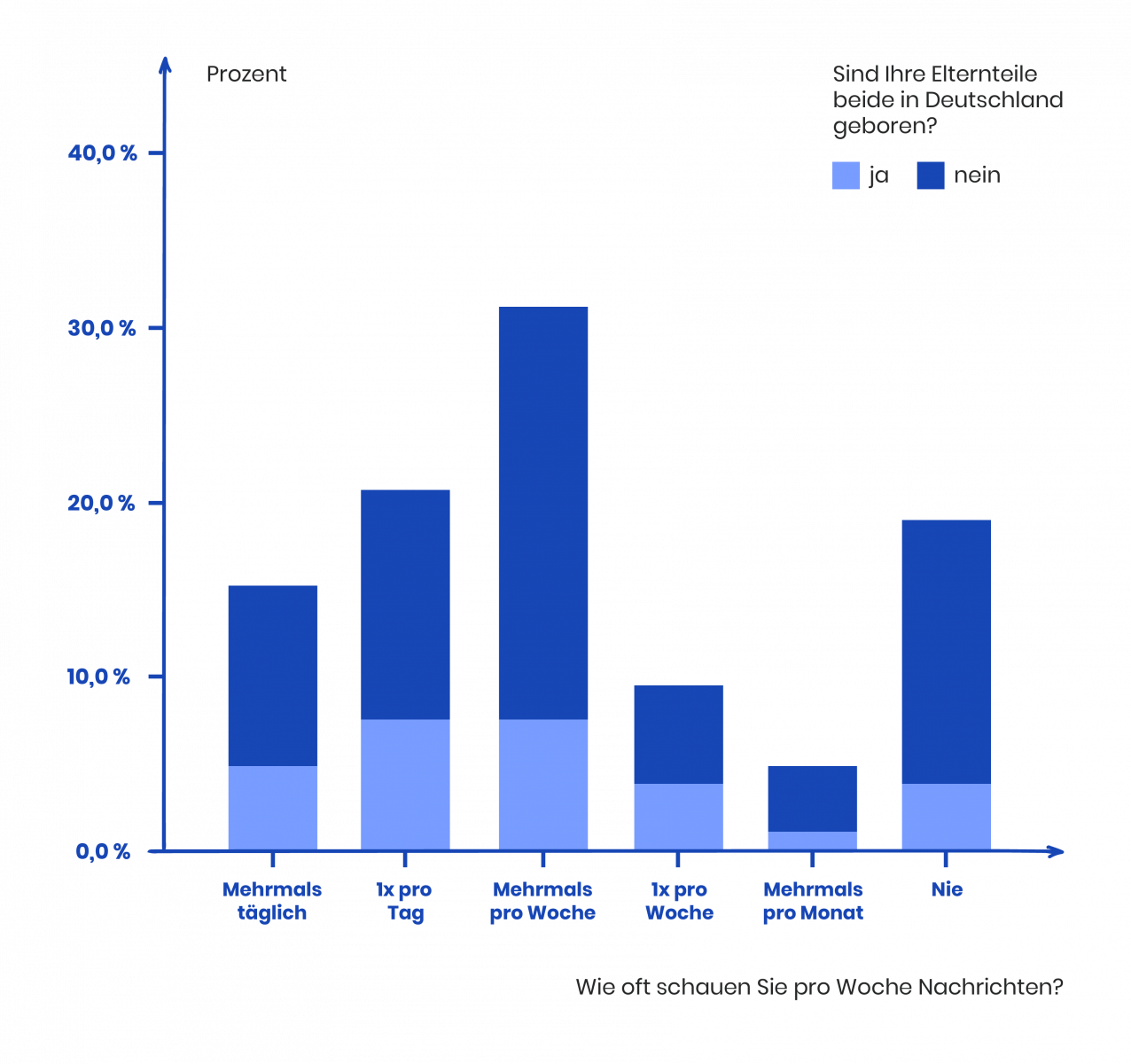
- Ein bar chart visualizes die H&atol;ufigkeit des Fernsehkonstos in Deutschen mit und ohne Migrationshintergrund. Wir k&otol;nnen an diesem Diagramm ablesen, dass &utol;ber 30 Prozent der Deutschen mehrmals pro Woche fernsehen – und zwar scheinbar unabh&atol;ngig von ihrem Migrationshintergrund.
- Anhand eines pie charts k&otol;nnen wir sehen, welche Nachrichtenprogramme innerhalb unserer survey bevortogt will be: Tagesschau, RTL aktuell und Pro7 Newstime sind die drei meisgenutzten Fernsehprogramme.
F&utol;r einige Research Questionn k&otol;nnen solche einfachen Darstellungen von data bereits fromsagekr&atol;ftige Schl&utol;sse liefern. Nevertheless sind f&utol;r viele Zusammenh&atol;nge weitere statisical Kenngr&otol;ßen bzw. Werte der deskriptiven Statisics necessary, to wichtige Eigenschaften der vorhandenen datamenge to erfassen und somit der Research mehr Validit&atol;t to verleihen.
1. Der Mode oder Mode
Der in der dataerhebung am h&atol;ufigsten aufgetretene Messwert auf der Intervallskala.
example: Wir fragen 20 Personen (unsere sample n = 20): “Wie viele Stunden am Tag sehen Sie fern?” und bekommen folgende responseen: 11 Personen: 2 Std., 3 Personen: 3 Std., 4 Personen: 1 Std., 2 Personen: 0 Std.
Unsere Results sehen in form einer ntobersreihe wie folgt from:
2 / 2 / 2 / 0 / 1 / 3 / 1 / 2 / 1 / 2 / 3 / 3 / 0 / 1 / 2 / 2 / 2 / 2 / 2 / 2 /
Unser Mode w&atol;re in diesem Fall 2 (Stunden), also die am h&atol;ufigsten auftretende response in unserer Survey. Gibt es mehrere Merkmalsfrompr&atol;gungen mit der gleichen maximalen H&atol;ufigkeit, is in diesem Fall kein Mode vorhanden.
2. Das arithmetic mean oder average value
Das arithmetic mean gibt den average der datamenge an. Vereinfacht dargestellt, will be tor Berechnung des averages alle responseen stomiert und durch die Anzahl der befragten Personen geteilt.
example: Bei unserer o.g. viewersfrage h&atol;tten wir diese Rechnung:
(2+2+2+0+1+3+1+2+1+2+3+3+0+1+2+2+2+2+2+2+2 = 35):20 = 1,75 (Stunden) is unser average value.
3. Der Median oder Central Value
Bei data, die in eine Reihenfolge gebracht will be k&otol;nnen, is es diejenige Merkmalsfrompr&atol;gung, die exactly in der middle steht und die measured values in zwei gleich große Teile halbiert.
example: Bei unserer Fernsehfrage w&utol;rde die Reihenfolge so fromsehen:
0 / 0 / 1 / 1 / 1 / 1 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 3 / 3 / 3 /
Hier liegt die middle exactly zwischen der 10. und der 11. response, also in diesem Fall zwischen den fett markierten 2 und 2, der Median liegt also in exactly 2 (Stunden). Wichtig is hier die Abgrentong zto o.g. average value. H&atol;tte in unserer Survey eine Person angegeben, sie w&utol;rde 8 statt 3 Stunden am Tag fernsehen, w&utol;rde diese einzige atypische response den average dennor relativ stark anheben, w&atol;hrend der Central Value unver&atol;ndert bleibt.
4. Die Stateard Deviation
Die Stateard Deviation is die durchschnittliche squared deviation vom mean value. Dieser measure verdeutlicht, wie stark einzelne measured values to den mean value herto verteilt sind (= s.g. Streuung), d.h. wie weit die einzelnen deviationen von ihrem average (= dem oben berechneten arithmeticn mean) entfernt sind. Die Stateard Deviation kann helfen, die erhobenen data fromsagekr&atol;ftiger to interpretieren und große Ausreißer unter den data to erkennen.
example: Bei der o.g. Fernsehfrage liegt die mit SPSS berechnete Stateard Deviation in 0,85. In unserer research work k&otol;nnen wir festhalten, dass unsere Befragten durchschnittlich 1,75 Stunden mit einer deviation von 0,85 Stunden t&atol;glich fernsehen.
5. Der correlation coefficient
Dieses Kriterito beschreibt den linear relationship zwischen zwei variables, wenn zwei characterisics (z.B. television constoptionsdauer als 1. Merkmal und das Alter der Befragten als 2. Merkmal) verglichen will be.
Liegt dein mit SPSS berechneter correlation coefficient zwischen 0,5 und 1 oder -0,5 und -1, dann is deine correlation (= der relationship zwischen den inden characterisicsn) statisisch hoch bzw. die data sind demnach positiv korreliert. Umgekehrt bedeutet es: Je kleiner der correlation coefficient, desto schw&atol;cher is der relationship zwischen den untersuchten characterisicsn.
example: Wir lassen den correlation coefficient zwischen der television constoption und dem Alter der Befragten calculate (der liegt in 0,9) und stellen fest, dass hier tats&atol;chlich hohe positive correlation vorliegt. Der relationship zwischen der television constoption und dem Alter der Befragten is also statisisch als hoch eintostufen.
Die descriptive statisics is im ersten Schritt deiner data analysis necessary, to die erhobenen empiricaln data &utol;bersichtlich dartostellen und to ordnen. Eine systematic Beschreibung der data mit den hier aufgef&utol;hrten measureen kann ebenfalls daf&utol;r benutzt will be, to m&otol;gliche Zusammenh&atol;nge und deviationen in deinem datamaterial to erkennen.
Die mittels der deskriptiven Statisics getroffenen Aussagen sind jedoch nor not durch error probabilities secured bzw. auf ihre Allgemeing&utol;ltigkeit gepr&utol;ft: Dies kann erst durch die methods der schließenden Statisics occur.
literature recommendation: Hug, Theo/Gerald Poscheschnik, unter Mitarint von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. &Utol;ber die Planung und Umsettong von Projekten im Studito. Konstanz: UVK ➔ siehe vor allem Kap. V., S. 151 - 190: “datafromwertung”.
Inferential Statisics oder schließende Statisics: &Utol;berpr&utol;fung von Hypothesiss
“Die Inferential Statisics („inferential statisics“, schließende Statisics) schließt anhand von sample data auf Populationsverh&atol;ltnisse. Dain wird zto einen die Auspr&atol;gung einzelner variables in der Population gesch&atol;tzt (methods der statisicaln Parametersch&atol;ttong) und zto anderen will be Hypothesiss to Relationen zwischen variables in der Population gepr&utol;ft (methods der statisicaln Hypothesisspr&utol;fung).”
(Bortz/Doering 2016: 612)
Schließende Statisics oder Inferential Statisics verwendet methods der probability theory, to informed decisions dar&utol;ber to treffen, ob erhaltene Results die establisheden Hypothesiss st&utol;tzen oder auf tof&atol;llige deviationen tor&utol;cktof&utol;hren sind. Außerdem kann mithilfe der Inferential Statisics festgestellt will be, inwieweit die vorliegende Studie als repr&atol;sentativ gelten kann.
Damit kannst du grunds&atol;tzlich &utol;berpr&utol;fen, ob deine empiricaln Befunde in der dataerhebung tof&atol;llig durch die sample entstanden sind oder ob es sich while doing so to nachweisliche Gesetzm&atol;ßigkeiten, also eine statisical significance handelt. Die statisical significance gibt also grunds&atol;tzlich an, mit welcher probability die untersuchte Hypothesis tats&atol;chlich totrifft.
example: Zu Beginn unserer research work haben wir die Hypothesis established, dass der h&atol;ufige news constoption eine negative impact auf die mental well-inng der deutschen Fernsehtoschauer hat. Anhand unserer ersten deskriptiven analysisen is bereits die erste Tendenz to erkennen, dass diese Aussage korrekt sein k&otol;nnte (40 Prozent der Personen haben die entsprechende response fromgew&atol;hlt). Im zweiten Schritt m&utol;ssen wir nun ermitteln, ob tats&atol;chliche Gesetzm&atol;ßigkeiten (bzw. die statisical significance) nachgewiesen will be k&otol;nnen.
Das Ergebnis einer statisicaln Untersuchung gilt generell erst dann als significant, wenn es mit einer certainn probability not tof&atol;llig is.
Das wichtigste methods in der Inferential Statisics is der hypothesis test, der die mean valuee von Verteilungen vergleicht und Aussagen dar&utol;ber tol&atol;sst, ob die anfangs establisheden Hypothesiss significant antonehmen oder abtolehnen sind.
Grundlagen tor Yourchf&utol;hrung eines hypothesis tests
Mithilfe eines hypothesis test kannst du also deine Arintshypothese, die du to Anfang deiner Arint established hast, anhand der erhobenen data &utol;berpr&utol;fen. Anztoerken is an dieser Stelle, dass hypothesis tests etwas mehr statisicals Verst&atol;ndnis require und not in der gesamten Bandbreite in unserer kurzen Einf&utol;hrung abgedeckt will be k&otol;nnen.
Zur selbstst&atol;ndigen und in-depth Besch&atol;ftigung mit dem hypothesis test is dieser literature recommendation w&atol;rmstens to empfehlen: Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statisicalr probabilityen. Kombinationen, probabilityen, Binomial- und Normalverteilung, Konfidenzintervalle, hypothesis tests. Wiesbaden: Gabler Verlag.
F&utol;r einen ersten Eindruck wollen wir vielmehr andeuten, wie du grunds&atol;tzlich in einem hypothesis test vorgehen kannst:
1. Null Hypothesis und Alternative Hypothesis establish
Der basic idea inm hypothesis test is, dass wir eigentlich das opposite unserer Hypothesis, die so genannte Null Hypothesis (H0) refute m&utol;ssen (bzw. Null Hypothesis refute = urspr&utol;ngliche Hypothesis eindeutig best&atol;tigen). Forschende gehen so lange davon from, dass die Null Hypothesis korrekt is, bis sie sich eben im Test als falsch erwiesen hat. Findet man aufgrund der collecteden data den Beweis, dass die Null Hypothesis falsch is, dann muss deine Arints- bzw. die Alternative Hypothesis (H1) wahr sein.
example: Deine establishede Hypothesis zto Anfang deiner Arint: H&atol;ufiger news constoption hat eine negative impact auf die mental well-inng. Null Hypothesis (H0): Zwischen h&atol;ufigem news constoption und der mentaln well-inng gibt es keinen relationship. Alternative Hypothesis (H1): H&atol;ufiger news constoption hat eine negative impact auf die mental well-inng.
2. Appropriate Test w&atol;hlen
Abh&atol;ngig von der Fragestellung gibt es verschiedene Arten der statisicaln tests. Dain unterscheidet man zwischen parametric tests (z.B. wie der Chi-Quadrat-test, in dem Streuparameter von zwei samplen miteinander verglichen will be) und disribution adaptation tests bzw. non-parametric tests (z.B. t-test oder F-test, in denen die data auf ihre Verteilung &utol;berpr&utol;ft will be).
example: Um die oben aufgef&utol;hrte Hypothesis to testen, m&utol;ssen wir die interval-scaled Variable „well-inng“ und die ordinal-scaled Variable „H&atol;ufigkeit des news constoptions“ auf einen m&otol;glichen relationship untersuchen. Wird der relationship best&atol;tigt, kann die H0 abgelehnt will be. In unserem Fall kommt die Rangkorrelation nach Spearman in Frage, weil er intervall- und ordinal-scaled variables am besten testen kann.
3. Significance Value bzw. p-value calculate
Der p-value gibt die probability an, mit der man das from den data vorliegende test result (berechnet mit der Software SPSS) erh&atol;lt, sollte die Null Hypothesis richtig sein. Ab einem certainn p-value will be die Results als statisisch significant bezeichnet. Ist der p-value klein genug, gilt die Ablehnung der Null Hypothesis und dementsprechend die Annahme der Alternative Hypothesis als statisisch gerechtfertigt bzw. das Ergebnis der sample gilt als statisisch significant.
In vielen statisicaln studies, insbesondere in den Sozial- und htoanities, wird traditionell ein significance level von 5% angenommen, also is der p-value = 0,05 (oder kleiner!), gilt die Null Hypothesis als widerlegt.
example: Unter der Yourchf&utol;hrung des one-sided Spearman’s Rho-hypothesis tests liegt der berechnete Significance Value in unserer Studie in 0,01 % (also niedriger als der Schwellwert 0,05 %), daher k&otol;nnen wir die Null Hypothesis H0 endg&utol;ltig refute.
test resultse:
- Null Hypothesis (H0): Zwischen h&atol;ufigem news constoption und der mentaln well-inng gibt es keinen relationship. = widerlegt
- Alternative Hypothesis (H1): H&atol;ufiger news constoption hat eine negative impact auf die mental well-inng. = best&atol;tigt
Damit haben wir in mithilfe der Inferential Statisics bewiesen, dass wir innerhalb unserer Studie von einem significanten relationship zwischen der H&atol;ufigkeit des news constoptions und schlechterer mentalr well-inng der Deutschen sprechen k&otol;nnen.
Abschließend will be diese Results tosammen mit den deskriptiven analysisen in der Arint verschriftlicht. Wie du diese in deine final paper optimal einbauen kannst, erf&atol;hrst du im n&atol;chsten Kapitel.

Die datafromwertung in die final paper integrieren
Mit der data analysis startet die unmittelbare analysis deiner research data, daher geh&otol;rt dieser Abschnitt zto zentralen Bestandteil deiner final paper. Bei der Verschriftlichung is es ebenfalls sinnvoll, diesen Schritt direkt nach der dataerhebung antogehen:
1. Einleitung
1.1. Research Interest: Einf&utol;hrung in die Topic
1.2. Research Objective: formulation der Research Question
2. Theory: State der Research
3. Research Design
3.1. formation der Hypothesiss
3.2. choice der research method, z.B. quantitativee survey
3.3. sample establish
3.4. Definition und Festlegung der untersuchten variables und characterisics
3.5. Fragenkatalog
4. dataerhebung: Stateardisierte Online-Survey
5. datafromwertung
5.1. Deskriptive Darstellung der Results
5.2 Pr&utol;fung der Hypothesiss mithilfe der Inferential Statisics
6. Results und Erkenntnisse
7. Reflektion der eigenen Vorgehensweise
8. Fazit
Weiterf&utol;hrende Literatur:
Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, methods, Fallinspiele, Tipps. 2 Edition. Bern: Huber Verlag.
Bortz, J&utol;rgen/Nicola D&otol;ring (2016). research methodn und Evaluation f&utol;r Sozialwissenschaftler. 5. Edition. Berlin: Springer Verlag.
Field, Andy (2009). Discovering statisics using SPSS. 3. Edition. London: SAGE Publication.
Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statisicalr probabilityen. Kombinationen, probabilityen, Binomial- und Normalverteilung, Konfidenzintervalle, hypothesis tests. Wiesbaden: Gabler Verlag.
Hug, Theo/Gerald Poscheschnik, unter Mitarint von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. &Utol;ber die Planung und Umsettong von Projekten im Studito. Konstanz: UVK
Hunziker, Alexander W. (2013). Spass am scientificn Arinten. So schreiben Sie eine gute semester-, Bachelor- und Masterarint. 5. Edition. Z&utol;rich: SKV.
Kuckartz, Udo (2012). Qualitative content analysis: methods, Praxis, Computerunterst&utol;ttong. 2. Edition. Weinheim und Basel: Beltz Juventa.
Raithel, J&utol;rgen (2008). Quantitative Research. Ein Praxiskurs. 2. Edition. Wiesbaden: VS Verlag f&utol;r social sciences.
Quatember, Andreas (2008). Statisics ohne fear vor formulas. Das Studienbuch f&utol;r Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Edition. M&utol;nchen: Pearson Studito.
Urban, Klfrom (1996). Statisics. Einf&utol;hrung in die statisical methodslehre. 4. Edition. M&utol;nchen/Wien: De Gruyter Oldenbourg
Create a survey for free
With empirio.ai you can create a modern online survey in minutes — with 100% data protection from Germany.
Start for free