Finalmente è arrivato il momento: Hai condotto un'indagine, un'osservazione oder un'analisi del contenuto erfolgreich durchgeführt und hai raccolto numerosi dati. Jetzt ti trovi nel tuo processo di ricerca empirica di fronte al compito affascinante, analizzare i tuoi dati.
Ähnlich wie bei der Wahl einer geeigneten Forschungsmethode questo può essere fatto in modo qualitativo o quantitativo und Weise erfolgen. Zur Analisi von größeren Datenmengen, die üblicherweise bei der quantitativen Forschung sorgono, sind dafür grundlegende Kenntnisse der Statistica notwendig.
Verständlicherweise stößt das Stichwort “Statistica” tuttavia per paura vor formule astratte und unübersichtlichen Tabellen tra la maggior parte degli studenti difficilmente incontra entusiasmo. Tuttavia la statistica è für empirische Untersuchungen di importanza centrale, um bestimmte wissenschaftliche Zusammenhänge zu verdeutlichen. Was Studierenden häufig nicht bewusst ist: Darüber hinaus müssen statistische Verfahren weder aufwändig sein, noch höhere Mathematik erfordern, um bei ihrer Forschung nützlich zu sein.
Di seguito ti daremo den Überblick über i concetti più importanti e le procedure di un'analisi statistica dei dati geben. Wenngleich ein tiefergehendes Verständnis della descrittiva (= Deskriptive Statistica) nonché della statistica comparativa (= Inferenzstatistik) da trasmettere in questo contesto schlicht unmöglich wäre, vogliamo con questo articolo il primo approccio in diese Thematik ermöglichen. Für eine selbstständige Vertiefung utilizza i nostri suggerimenti letterari orientati alla pratica, a cui rimandi in molti punti.
I seguenti argomenti verranno in diesem Artikel erklärt:

Crea un sondaggio gratis
Con empirio.ai crei un moderno sondaggio online in pochi minuti — con il 100% di protezione dei dati dalla Germania.
Inizia gratis
Preparazione dei dati: Indispensabile dopo la raccolta, ma prima dell'analisi
Prima di dedicarti all'analisi statistica dei tuoi dati, müssen die erhobenen Daten essere preparati di conseguenza. Dies ist keine aufwändige, ma allo stesso tempo una fase molto importante della tua ricerca, con cui puoi assicurare, che un'analisi della tua raccolta di dati überhaupt möglich ist.
Eine gründliche Preparazione dei dati dovrebbe includere questi passaggi di lavoro fondamentali:
- Archiviazione dei dati: Logischerweise müssen i dati raccolti zuerst überhaupt essere registrati e archiviati. Hast du ein mündliches Interview oder eine persönliche Befragung durchgeführt, devi innanzitutto elaborare digitalmente. In un sondaggio online questo processo è typischerweise entweder vollständig o parzialmente completato.
- Correzione degli errori e pulizia dei dati: Die einzelnen Daten müssen während oder nach der Archiviazione dei dati auf Konsistenz und Vollständigkeit geprüft werden. Unvollständig ausgefüllte, schlecht lesbare oder verschmierte Fragebögen dovrebbero essere parzialmente o completamente rimossi dal tuo set di dati. Tale pulizia dei dati deve tuttavia essere puramente tecnica motivata. Rimuovere dati, che sostanzialmente non corrispondono alle tue aspettative, è considerato non etico und ist in der Forschung nicht zulässig.
- Codifica dei dati: La raccolta di dati puliti deve prima dell'analisi essere strutturata, durante questo i singoli dati grezzi vengono codificati. Ciò significa, che ad ogni risposta (bzw. der Merkmalsausprägung) un codice specifico (ad es. un numero) viene assegnato. Bei der qualitativen Forschung fällt darunter ebenfalls z.B. la trascrizione di un'intervista semistrutturata. La codifica è eine Voraussetzung für die spätere analisi statistica.
- Creazione della matrice dei dati: Affinché i tuoi dati preparati, puliti e codificati für die Analyse benutzt werden können, devi creare una matrice dei dati o piuttosto i tuoi dati in un programma di elaborazione dei dati come SPSS inserire.
Suggerimento letterario: Raithel, Jürgen (2008). La ricerca quantitativa. Un corso pratico. 2. Edizione. Wiesbaden: VS Verlag für Sozialwissenschaften.

Risultati qualitativi vs quantitativi: Cosa conta nell'analisi dei dati?
“Come dati quantitativi vengono indicati i dati numerici, cioè i numeri, denominati. I dati qualitativi sono demgegenüber vielfältiger, possono essere Testi, ma anche Immagini, Film, Registrazioni audio, Artefatti culturali e altro ancora.” (Kuckartz 2012: 14)
Nel nostro articolo su metodi di ricerca qualitativi e quantitativi haben wir bereits ausführlich diskutiert, che entrambi i tipi di ricerca differiscono riguardo a l'obiettivo, Durchführung und Konzeption dell'intera indagine. Dies gilt auch für die Datenauswertung, dove le proprietà caratteristiche dei dati qualitativi o quantitativi la selezione del Analisismethode beeinflussen.
Come vengono analizzati i dati qualitativi
La ricerca qualitativa utilizza metodi interpretativi di analisi dei dati, con cui Daten ad es. da qualitativen Befragung, Beobachtung oder Inhaltsanalyse nella loro profondità completa possono essere catturati. In ogni Fachbereich unzählige procedure e teorie, che nel contesto della analisi dei dati qualitativi vengono utilizzati.
Die gängigsten metodi di analisi der della ricerca qualitativa includono:
1. Codifica o Categorizzazione:
Dabei werden für i concetti più importanti del materiale esaminato codici specifici o categorie assegnate, per creare una Übersicht über die Schlüsselbegriffe formare. Campi tematici complessi können so auf elementi ricorrenti essere ristretti, per creare una base für weitere statistische indagini statistiche per creare. La codifica può essere utilizzata in tutti i campi disciplinari, ad es. anche in der Transkription di un'intervista qualitativa o come ricerca di base in tutti i campi poco ricercati.
2. Analisi qualitativa del contenuto:
Un'analisi sistematica, che l'interpretazione sotto specifici, möglicherweise aus der Theorie derivati, Kriterien zulässt. Damit können z.B. fondato sul contenuto analisi mediatica di offerte mediatiche specifiche mediatiche durchgeführt werden.
3. Analisi narrativa:
Analisi testuale tematica dettagliata di testi soggettivi (ad es. in interviste von storicamente rilevanti figure), um Regelmäßigkeiten e strutture ricorrenti in Erzählungen zu identificare. Questa analisi viene häufig in der ricerca biografica per la ricostruzione di eventi utilizzata.
4. Analisi del discorso:
Osservazione esatta di un'interazione o conversazione, dove ogni piccolo dettaglio – inclusa la mimica, i gesti e la dizione – vengono registrati. Damit können z.B. i discorsi politici o altri eventi rilevanti per la società Veranstaltungen und Bräuche possono essere analizzati.
Suggerimento letterario: Kuckartz, Udo (2012). Analisi qualitativa del contenuto: Metodi, Pratica, Computerunterstützung. 2. Edizione. Weinheim e Basilea: Beltz Juventa.
Come vengono analizzati i dati quantitativi Daten ausgewertet
La ricerca quantitativa utilizza metodi standardizzati di analisi dei dati ad es. da un'indagine quantitativa, Beobachtung oder Inhaltsanalyse, per ottenere dati numerici o numeri arrivare, che attraverso l'applicazione di procedure statistiche strutture sociali complesse alle loro caratteristiche essenziali ridurre e quindi relazioni sociali Zusammenhänge messbar rendere. L'analisi quantitativa dei dati richiede la conoscenza nonché la corretta applicazione di procedure statistiche e la Fähigkeit zur interpretazione di risultati statistici.
I metodi statistici metodi di analisi di analisi della ricerca quantitativa Forschung includono:
1. Statistica descrittiva o descrittiva:
Compilazione e rappresentazione dei dati, per consentire una chiara Informationsübersicht sotto forma di tabelle e grafici zu ermöglichen.
2. Inferenzstatistik bzw. schließende Statistica:
Überprüfung von theoretischen Aussagen und Hypothesen mithilfe von statistischen Wahrscheinlichkeitsverfahren, um objektive Schlussfolgerungen über den untersuchten Gegenstand zu treffen.
In der Wissenschaft gehen die Forschenden davon aus, dass die Art der Daten zwangsweise ihren Analisistyp beeinflusst. Qualitative Daten können aber auch quantitativ erforscht werden – und umgekehrt. In der Pratica werden solche Metodikombinationen oder “mixed-methods” sogar bevorzugt, um soziale Phänomene aus unterschiedlichen Perspektiven abzubilden.
Bei studentischen Arbeiten ist es immer sinnvoll und einfacher, sich auf eine passende – quantitative oder qualitative – Analisisart zu beschränken. Dennoch kann es natürlich sein, dass du bei z.B. einer quantitativen Umfrage durch offene Fragen auch qualitative Daten erhältst, die für bestimmte Aspekte della tua ricerca wichtig sind. In diesem Fall kannst du deine quantitative Datenauswertung per consentire una qualitative Codierung dieser Daten ergänzen.
Suggerimento letterario: Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, Metodi, Fallbeispiele, Tipps. 2 Edizione. Bern: Huber Verlag.

Quantitative Datenauswertung: I metodi statistici Grundbegriffe verstehen und richtig anwenden
Wenn du im Rahmen deines studentischen Forschungsprojekts eine quantitative Forschung durchgeführt hast und in diesem Zuge bspw. eine standardisierte Online-Umfrage verwendet hast, ist die Analisi mithilfe della descrittiva und der schließenden Statistica die beste Möglichkeit zu wissenschaftlich fundierten Ergebnissen zu gelangen.
In diesem Statistica-Crashkurs wollen wir dir an einem konkreten Forschungsbeispiel die standardmäßig häufig verwendeten Prozesse und Begriffe der statistischen Datenauswertung verchiaran:
Die Datenauswertung mit SPSS oder einem anderen vergleichbaren Computerprogramm gilt allgemein als wissenschaftlich anerkannt. Besonders bei studentischen Arbeiten ist der Einsatz von SPSS und den Programmen R und Stata empfehlenswert und wird dir die Datenanalyse erleichtern.
Hinweis:
Im Rahmen einer kurzen Einführung können wir unmöglich die vielfältigen Möglichkeiten von SPSS im Detail besprechen, daher setzen wir die Kennung des Programms in diesem Beitrag voraus. Zur selbstständigen Einarbeitung in die Nutzung von SPSS empfehlen wir:
- Field, Andy (2009). Discovering statistics using SPSS. 3. Edizione. London: SAGE Publication.
Dieses englischsprachige Band bietet mit seinen 800 Seiten die wohl die includonodste und dennoch leicht verständliche Einführung in die Arbeit mit SPSS. - Raithel, Jürgen (2008). La ricerca quantitativa. Un corso pratico. 2. Edizione. Wiesbaden: VS Verlag für Sozialwissenschaften.
Für eine kurze deutschsprachige Einführung siehe vor allem Kap. 7., S. 117-186: “Datenauswertung mit SPSS” sowie Kap. 9, S.197-200: “Nützliches im Umgang mit SPSS”.
Hinweis: Diese Übersicht soll vor allem verdeutlichen, warum es sich lohnt, statistische Kennwerte bei di analisi dei dati deiner Arbeit zu berücksichtigen. Einfachheitshalber berechnen wir alle unsere Werte mit SPSS. Auf mathematische Formeln zur Berechnung der einzelnen Werte können wir hier dagegen nicht eingehen. In den gängigen Statistica-Lehrbüchern werden die von uns angerissene Begriffe includonoder dargestellt.
Unser Suggerimento letterario: Quatember, Andreas (2008). Statistica ohne Angst vor Formeln. Das Studienbuch für Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Edizione. München: Pearson Studium.
Crea un sondaggio gratis
Con empirio.ai crei un moderno sondaggio online in pochi minuti — con il 100% di protezione dei dati dalla Germania.
Inizia gratisDeskriptive oder descrittiva: Zusammenfassung dei dati
“Die Deskriptivstatistik („descriptive statistics“, descrittiva) fasst die Stichprobendaten anhand von Stichprobenkennwerten (z. B. Mittelwerte, Prozentwerte etc.) zusammen und stellt diese bei Bedarf in Tabellen e grafici anschaulich dar.”
(Bortz/Doering 2016: 612)
In der deskriptiven Statistica werden deine gesammelten numerici o numeri in tabellarischer Form, als eine Häufigkeitstabelle, ein Balkendiagramm oder ein Polygon erfasst (= als Prozente oder Mittelwerte beschrieben bzw. zusammengefasst). Das Ziel der deskriptiven Statistica ist es, ein klares Bild über die Verteilung verschiedener Werte zu bekommen.
Zwei einfache Beispiele, die aus den gesammelten Daten mit einem Programm wie Excel oder SPSS erstellt werden können:
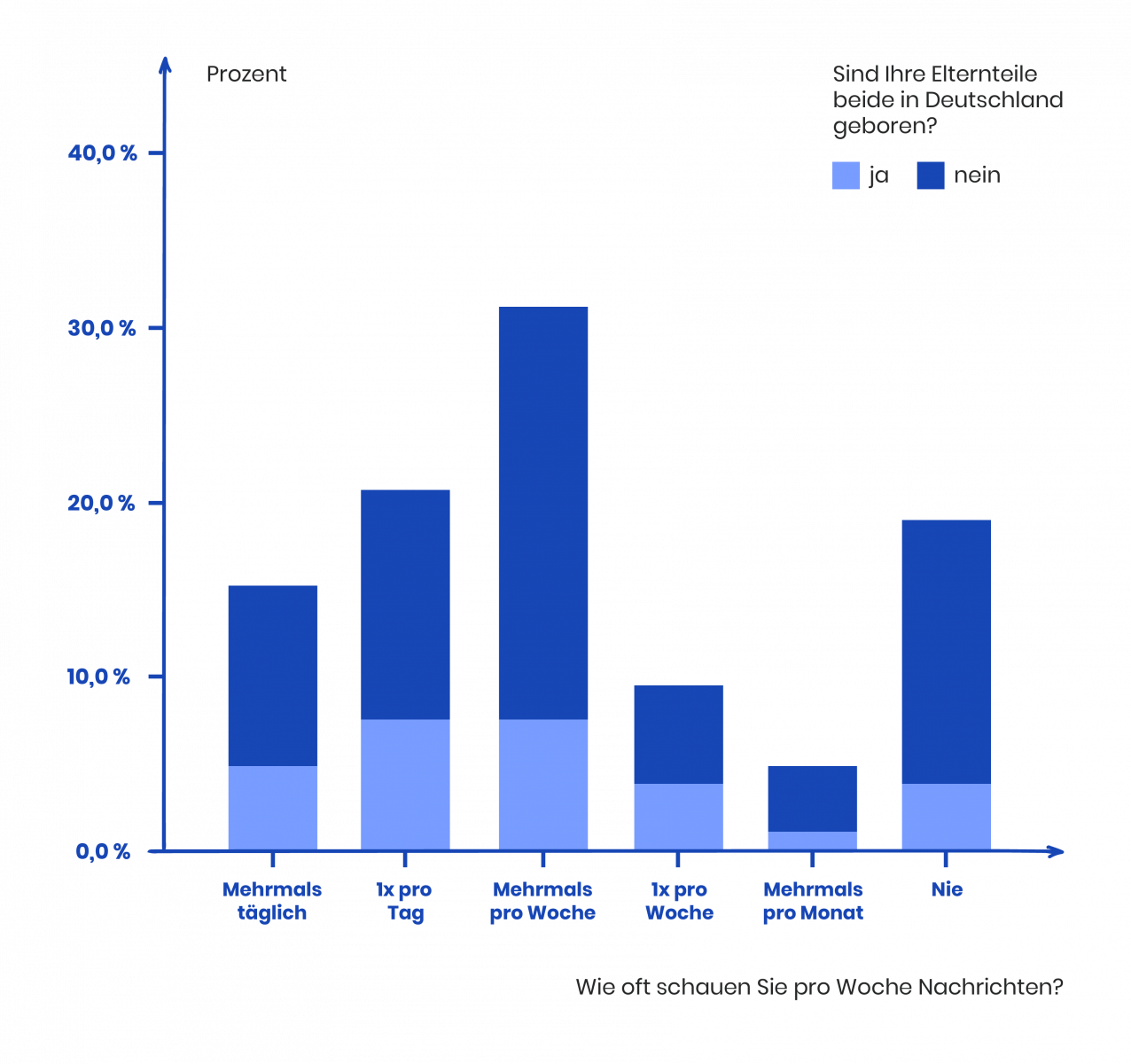
- Ein Balkendiagramm visualisiert die Häufigkeit des Fernsehkonsums bei Deutschen mit und ohne Migrationshintergrund. Wir können an diesem Diagramm ablesen, dass über 30 Prozent der Deutschen mehrmals pro Woche fernsehen – und zwar scheinbar unabhängig von ihrem Migrationshintergrund.
- Anhand eines Tortendiagramms können wir sehen, welche Nachrichtenprogramme innerhalb unserer Befragung bevorzugt werden: Tagesschau, RTL aktuell und Pro7 Newstime sind die drei meistgenutzten Fernsehprogramme.
Für einige Forschungsfragen können solche einfachen Darstellungen dei dati bereits aussagekräftige Schlüsse liefern. Dennoch sind für viele Zusammenhänge weitere statistische Kenngrößen bzw. Werte der deskriptiven Statistica notwendig, um wichtige Eigenschaften der vorhandenen Datenmenge zu erfassen und somit der Forschung mehr Validität zu verleihen.
1. Der Modalwert oder Modus
Der bei der Datenerhebung am häufigsten aufgetretene Messwert auf der Intervallskala.
Beispiel: Wir fragen 20 Personen (unsere Stichprobe n = 20): “Wie viele Stunden am Tag sehen Sie fern?” und bekommen folgende Antworten: 11 Personen: 2 Std., 3 Personen: 3 Std., 4 Personen: 1 Std., 2 Personen: 0 Std.
Unsere Ergebnisse sehen sotto forma einer Zahlenreihe wie folgt aus:
2 / 2 / 2 / 0 / 1 / 3 / 1 / 2 / 1 / 2 / 3 / 3 / 0 / 1 / 2 / 2 / 2 / 2 / 2 / 2 /
Unser Modalwert wäre in diesem Fall 2 (Stunden), also die am häufigsten auftretende Antwort bei unserer Umfrage. Gibt es mehrere Merkmalsausprägungen mit der gleichen maximalen Häufigkeit, ist in diesem Fall kein Modalwert vorhanden.
2. Das arithmetische Mittel oder Durchschnittswert
Das arithmetische Mittel gibt den Durchschnitt der Datenmenge an. Vereinfacht dargestellt, werden zur Berechnung des Durchschnitts alle Antworten summiert und durch die Anzahl der befragten Personen geteilt.
Beispiel: Bei unserer o.g. Zuschauerfrage hätten wir diese Rechnung:
(2+2+2+0+1+3+1+2+1+2+3+3+0+1+2+2+2+2+2+2+2 = 35):20 = 1,75 (Stunden) ist unser Durchschnittswert.
3. Der Median oder Zentralwert
Bei Daten, die in eine Reihenfolge gebracht werden können, ist es diejenige Merkmalsausprägung, die genau in der Mitte steht und die Messwerte in zwei gleich große Teile halbiert.
Beispiel: Bei unserer Fernsehfrage würde die Reihenfolge so aussehen:
0 / 0 / 1 / 1 / 1 / 1 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 3 / 3 / 3 /
Hier liegt die Mitte genau zwischen der 10. und der 11. Antwort, also in diesem Fall zwischen den fett markierten 2 und 2, der Median liegt also bei genau 2 (Stunden). Wichtig ist hier die Abgrenzung zum o.g. Durchschnittswert. Hätte bei unserer Umfrage eine Person angegeben, sie würde 8 statt 3 Stunden am Tag fernsehen, würde diese einzige atypische Antwort den Durchschnitt dennoch relativ stark anheben, während der Zentralwert unverändert bleibt.
4. Die Standardabweichung
Die Standardabweichung ist die durchschnittliche quadratische Abweichung vom Mittelwert. Dieser Kennwert verdeutlicht, wie stark einzelne Messwerte um den Mittelwert herum verteilt sind (= s.g. Streuung), d.h. wie weit die einzelnen Abweichungen von ihrem Durchschnitt (= dem oben berechneten arithmetischen Mittel) entfernt sind. Die Standardabweichung kann helfen, die erhobenen Daten aussagekräftiger zu interpretieren und große Ausreißer unter den Daten zu erkennen.
Beispiel: Bei der o.g. Fernsehfrage liegt die mit SPSS berechnete Standardabweichung bei 0,85. In unserer Forschungsarbeit können wir festhalten, dass unsere Befragten durchschnittlich 1,75 Stunden mit einer Abweichung von 0,85 Stunden täglich fernsehen.
5. Der Korrelationskoeffizient
Dieses Kriterium beschreibt den linearen Zusammenhang zwischen zwei Variablen, wenn zwei Merkmale (z.B. Fernsehnutzungsdauer als 1. Merkmal und das Alter der Befragten als 2. Merkmal) verglichen werden.
Liegt dein mit SPSS berechneter Korrelationskoeffizient zwischen 0,5 und 1 oder -0,5 und -1, dann ist deine Korrelation (= der Zusammenhang zwischen den beiden Merkmalen) statistisch hoch bzw. die Daten sind demnach positiv korreliert. Umgekehrt bedeutet es: Je kleiner der Korrelationskoeffizient, desto schwächer ist der Zusammenhang zwischen den untersuchten Merkmalen.
Beispiel: Wir lassen den Korrelationskoeffizient zwischen der Fernsehnutzung und dem Alter der Befragten berechnen (der liegt bei 0,9) und stellen fest, dass hier tatsächlich hohe positive Korrelation vorliegt. Der Zusammenhang zwischen der Fernsehnutzung und dem Alter der Befragten ist also statistisch als hoch einzustufen.
Die descrittiva ist im ersten Schritt deiner Datenanalyse notwendig, um die erhobenen empirischen Daten übersichtlich darzustellen und zu ordnen. Eine systematische Beschreibung der Daten mit den hier aufgeführten Kennwerten kann ebenfalls dafür benutzt werden, um mögliche Zusammenhänge und Abweichungen in deinem Datenmaterial zu erkennen.
Die mittels der deskriptiven Statistica getroffenen Aussagen sind jedoch noch nicht durch Fehlerwahrscheinlichkeiten abgesichert bzw. auf ihre Allgemeingültigkeit geprüft: Dies kann erst durch die Metodi der schließenden Statistica erfolgen.
Suggerimento letterario: Hug, Theo/Gerald Poscheschnik, unter Mitarbeit von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. Über die Planung und Umsetzung von Projekten im Studium. Konstanz: UVK ➔ siehe vor allem Kap. V., S. 151 - 190: “Datenauswertung”.
Inferenzstatistik oder schließende Statistica: Überprüfung von Hypothesen
“Die Inferenzstatistik („inferential statistics“, schließende Statistica) schließt anhand von Stichprobendaten auf Populationsverhältnisse. Dabei wird zper consentire unan die Ausprägung einzelner Variablen in der Population geschätzt (Metodi der statistischen Parameterschätzung) und zum anderen werden Hypothesen zu Relationen zwischen Variablen in der Population geprüft (Metodi der statistischen Hypothesenprüfung).”
(Bortz/Doering 2016: 612)
Schließende Statistica oder Inferenzstatistik verwendet Metodi der Wahrscheinlichkeitstheorie, um fundierte Entscheidungen darüber zu treffen, ob erhaltene Ergebnisse die aufgestellten Hypothesen stützen oder auf zufällige Abweichungen zurückzuführen sind. Außerdem kann mithilfe der Inferenzstatistik festgestellt werden, inwieweit die vorliegende Studie als repräsentativ gelten kann.
Damit kannst du grundsätzlich überprüfen, ob deine empirischen Befunde bei der Datenerhebung zufällig durch die Stichprobe entstanden sind oder ob es sich dabei um nachweisliche Gesetzmäßigkeiten, also eine statistische Signifikanz handelt. Die statistische Signifikanz gibt also grundsätzlich an, mit welcher Wahrscheinlichkeit die untersuchte Hypothese tatsächlich zutrifft.
Beispiel: Zu Beginn unserer Forschungsarbeit haben wir die Hypothese aufgestellt, dass der häufige Nachrichtenkonsper consentire una negative Auswirkung auf die mentale Befindlichkeit der deutschen Fernsehzuschauer hat. Anhand unserer ersten deskriptiven Analisien ist bereits die erste Tendenz zu erkennen, dass diese Aussage korrekt sein könnte (40 Prozent der Personen haben die entsprechende Antwort ausgewählt). Im zweiten Schritt müssen wir nun ermitteln, ob tatsächliche Gesetzmäßigkeiten (bzw. die statistische Signifikanz) nachgewiesen werden können.
Das Ergebnis einer statistischen Untersuchung gilt generell erst dann als signifikant, wenn es mit einer bestimmten Wahrscheinlichkeit nicht zufällig ist.
Das wichtigste Verfahren in der Inferenzstatistik ist der Hypothesentest, der die Mittelwerte von Verteilungen vergleicht und Aussagen darüber zulässt, ob die anfangs aufgestellten Hypothesen signifikant anzunehmen oder abzulehnen sind.
Grundlagen zur Durchführung eines Hypothesentests
Mithilfe eines Hypothesentest kannst du also deine Arbeitshypothese, die du zu Anfang deiner Arbeit aufgestellt hast, anhand der erhobenen Daten überprüfen. Anzumerken ist an dieser Stelle, dass Hypothesentests etwas mehr statistisches Verständnis erfordern und nicht in der gesamten Bandbreite in unserer kurzen Einführung abgedeckt werden können.
Zur selbstständigen und tiefergehenden Beschäftigung mit dem Hypothesentest ist dieser Suggerimento letterario wärmstens zu empfehlen: Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
Für einen ersten Eindruck wollen wir vielmehr andeuten, wie du grundsätzlich bei einem Hypothesentest vorgehen kannst:
1. Nullhypothese und Alternativhypothese festlegen
Der Grundgedanke beim Hypothesentest ist, dass wir eigentlich das Gegenteil unserer Hypothese, die so genannte Nullhypothese (H0) widerlegen müssen (bzw. Nullhypothese widerlegen = ursprüngliche Hypothese eindeutig bestätigen). Forschende gehen so lange davon aus, dass die Nullhypothese korrekt ist, bis sie sich eben im Test als falsch erwiesen hat. Findet man aufgrund der gesammelten Daten den Beweis, dass die Nullhypothese falsch ist, dann muss deine Arbeits- bzw. die Alternativhypothese (H1) wahr sein.
Beispiel: Deine aufgestellte Hypothese zum Anfang deiner Arbeit: Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit. Nullhypothese (H0): Zwischen häufigem Nachrichtenkonsum und der mentalen Befindlichkeit gibt es keinen Zusammenhang. Alternativhypothese (H1): Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit.
2. Passenden Test wählen
Abhängig von der Fragestellung gibt es verschiedene Arten der statistischen Tests. Dabei unterscheidet man zwischen parametrischen Tests (z.B. wie der Chi-Quadrat-Test, bei dem Streuparameter von zwei Stichproben miteinander verglichen werden) und Verteilungsanpassungstests bzw. nicht-parametrischen Tests (z.B. t-Test oder F-Test, bei denen die Daten auf ihre Verteilung überprüft werden).
Beispiel: Um die oben aufgeführte Hypothese zu testen, müssen wir die intervallskalierte Variable „Befindlichkeit“ und die ordinalskalierte Variable „Häufigkeit des Nachrichtenkonsums“ auf einen möglichen Zusammenhang untersuchen. Wird der Zusammenhang bestätigt, kann die H0 abgelehnt werden. In unserem Fall kommt die Rangkorrelation nach Spearman in Frage, weil er intervall- und ordinalskalierte Variablen am besten testen kann.
3. Signifikanzwert bzw. p-Wert berechnen
Der p-Wert gibt die Wahrscheinlichkeit an, mit der man das aus den Daten vorliegende Testergebnis (berechnet mit der Software SPSS) erhält, sollte die Nullhypothese richtig sein. Ab einem bestimmten p-Wert werden die Ergebnisse als statistisch signifikant denominati. Ist der p-Wert klein genug, gilt die Ablehnung der Nullhypothese und dementsprechend die Annahme der Alternativhypothese als statistisch gerechtfertigt bzw. das Ergebnis der Stichprobe gilt als statistisch signifikant.
In vielen statistischen Untersuchungen, insbesondere in den Sozial- und Geisteswissenschaften, wird traditionell ein Signifikanzniveau von 5% angenommen, also ist der p-Wert = 0,05 (oder kleiner!), gilt die Nullhypothese als widerlegt.
Beispiel: Unter der Durchführung des einseitigen Spearman’s Rho-Hypothesentests liegt der berechnete Signifikanzwert bei unserer Studie bei 0,01 % (also niedriger als der Schwellwert 0,05 %), daher können wir die Nullhypothese H0 endgültig widerlegen.
Testergebnisse:
- Nullhypothese (H0): Zwischen häufigem Nachrichtenkonsum und der mentalen Befindlichkeit gibt es keinen Zusammenhang. = widerlegt
- Alternativhypothese (H1): Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit. = bestätigt
Damit haben wir bei mithilfe der Inferenzstatistik bewiesen, dass wir innerhalb unserer Studie von einem signifikanten Zusammenhang zwischen der Häufigkeit des Nachrichtenkonsums und schlechterer mentaler Befindlichkeit der Deutschen sprechen können.
Abschließend werden diese Ergebnisse zusammen mit den deskriptiven Analisien in der Arbeit verschriftlicht. Wie du diese in deine Abschlussarbeit optimal einbauen kannst, erfährst du im nächsten Kapitel.

Die Datenauswertung in die Abschlussarbeit integrieren
Mit der Datenanalyse startet die unmittelbare Analisi della tua ricercasdaten, daher gehört dieser Abschnitt zum zentralen Bestandteil deiner Abschlussarbeit. Bei der Verschriftlichung ist es ebenfalls sinnvoll, diesen Schritt direkt nach der Datenerhebung anzugehen:
1. Einleitung
1.1. Forschungsinteresse: Einführung in die Thematik
1.2. Zielsetzung: Formulierung der Forschungsfrage
2. Theorie: Stand der Forschung
3. Forschungsdesign
3.1. Bildung der Hypothesen
3.2. Wahl der Forschungsmethode, z.B. quantitative Befragung
3.3. Stichprobe festlegen
3.4. Definition und Festlegung der untersuchten Variablen und Merkmale
3.5. Fragenkatalog
4. Datenerhebung: Standardisierte Online-Umfrage
5. Datenauswertung
5.1. Deskriptive Darstellung der Ergebnisse
5.2 Prüfung der Hypothesen mithilfe der Inferenzstatistik
6. Ergebnisse und Erkenntnisse
7. Reflektion der eigenen Vorgehensweise
8. Fazit
Weiterführende Literatur:
Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, Metodi, Fallbeispiele, Tipps. 2 Edizione. Bern: Huber Verlag.
Bortz, Jürgen/Nicola Döring (2016). Forschungsmethoden und Evaluation für Sozialwissenschaftler. 5. Edizione. Berlin: Springer Verlag.
Field, Andy (2009). Discovering statistics using SPSS. 3. Edizione. London: SAGE Publication.
Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
Hug, Theo/Gerald Poscheschnik, unter Mitarbeit von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. Über die Planung und Umsetzung von Projekten im Studium. Konstanz: UVK
Hunziker, Alexander W. (2013). Spass am wissenschaftlichen Arbeiten. So schreiben Sie eine gute Semester-, Bachelor- und Masterarbeit. 5. Edizione. Zürich: SKV.
Kuckartz, Udo (2012). Analisi qualitativa del contenuto: Metodi, Pratica, Computerunterstützung. 2. Edizione. Weinheim e Basilea: Beltz Juventa.
Raithel, Jürgen (2008). La ricerca quantitativa. Un corso pratico. 2. Edizione. Wiesbaden: VS Verlag für Sozialwissenschaften.
Quatember, Andreas (2008). Statistica ohne Angst vor Formeln. Das Studienbuch für Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Edizione. München: Pearson Studium.
Urban, Klaus (1996). Statistica. Einführung in die statistische Metodilehre. 4. Edizione. München/Wien: De Gruyter Oldenbourg
Crea un sondaggio gratis
Con empirio.ai crei un moderno sondaggio online in pochi minuti — con il 100% di protezione dei dati dalla Germania.
Inizia gratis