Nu is het zover: Je hebt een bevraging, observatie of inhoudsanalyse succesvol afgerond en hebt daarbij veel gegevens verzameld. Nu sta je in je empirisch onderzoeksproces voor de spannende taak om je gegevens te analyseren.
Net als bij de keuze van een geschikte onderzoeksmethode kan dit op kwalitatieve of kwantitatieve manier gebeuren. Voor de analyse van grotere gegevenssets, die meestal ontstaan bij kwantitatief onderzoek zijn basiskennis van statistiek noodzakelijk.
Begrijpelijkerwijs stuit het trefwoord “statistiek” echter uit angst voor abstracte formules en ondoorzichtige tabellen bij de meeste studenten nauwelijks op enthousiasme. Desondanks is statistiek voor empirische onderzoeken van centraal belang, om bepaalde wetenschappelijke verbanden duidelijk te maken. Wat studenten vaak niet beseffen: Bovendien hoeven statistische procedures noch kostbaar te zijn, noch hogere wiskunde te vereisen om nuttig te zijn voor hun onderzoek.
Hierna geven we je een overzicht van de belangrijkste begrippen en procedures van een statistische gegevensanalyse. Hoewel het onmogelijk is om dieper begrip van beschrijvende (= Beschrijvende Statistiek) en vergelijkende statistiek (= Inferentiële Statistiek) in dit kader over te brengen, willen we met dit artikel de allereerste introductie tot dit onderwerp mogelijk maken. Voor zelfstandige verdieping, raadpleeg onze praktijkgerichte literatuuraanbevelingen, waarnaar we op veel plaatsen verwijzen.
De volgende onderwerpen worden in dit artikel uitgelegd:

Gratis enquête maken
Met empirio.ai maak je in enkele minuten een moderne online enquête — 100% gegevensbescherming uit Duitsland.
Gratis beginnen
Gegevensbereiding: Onmisbaar na de verzameling, maar voor de analyse
Voordat je je aan de statistische analyse van je gegevens kunt wijden, moeten de verzamelde gegevens dienovereenkomstig worden voorbereid. Dit is geen omvangrijke, maar wel een zeer belangrijke fase van je onderzoek, waarmee je kunt garanderen dat analyse van je gegevensverzameling überhaupt mogelijk is.
Een grondige gegevensbereiding moet deze basisstappen bevatten:
- Gegevensopslag: Logischerwijs moeten de verzamelde gegevens eerst helemaal worden vastgesteld en opgeslagen. Heb je een mondeling interview of persoonlijke Befragung uitgevoerd, dan moet je de antwoorden eerst digitaal voorbereiden. Bij een onlineenquête is dit proces meestal geheel of gedeeltelijk voltooid.
- Fout- en gegevensreiniging: De individuele gegevens moeten tijdens of na de gegevensopslag op consistentie en volledigheid worden gecontroleerd. Onvolledig ingevulde, slecht leesbare of beschadigde vragenlijsten moeten gedeeltelijk of volledig uit je gegevensverzameling worden verwijderd. Zo'n gegevensreiniging mag echter zuiver technisch gemotiveerd zijn. Gegevens verwijderen die inhoudelijk niet aan je verwachtingen voldoen, wordt als onethisch beschouwd en is in onderzoek niet toegestaan.
- Gegevenscodering: De schoonmaak gemaakte gegevensverzameling moet voor analyse worden gestructureerd, waarbij individuele ruwe gegevens worden gecodeerd. Dit betekent dat aan elke respons (d.w.z. de eigenwaarde) een bepaalde code (bijv. een getal) wordt toegewezen. Bij qualitativen Forschung valt dit ook onder bijv. de transcriptie van een geleide interview. Codering is een voorwaarde voor latere statistische analyse.
- Creatie van de gegevensmatrix: Om je voorbereide, gereinigde en gecodeerde gegevens voor analyse te gebruiken, moet je een gegevensmatrix maken of je gegevens in een gegevensverwerkingsprogramma als SPSS invoeren.
Literatuuradvies: Raithel, Jürgen (2008). Kwantitatief Onderzoek. Een praktijkverloop. 2e druk. Wiesbaden: VS Verlag für Sozialwissenschaften.

Kwalitatieve versus kwantitatieve resultaten: Wat is belangrijk bij gegevensanalyse?
“Kwantitatieve gegevens zijn numerieke gegevens, dus getallen. Kwalitatieve gegevens daarentegen zijn veelvoudiger, het kunnen teksten zijn, maar ook afbeeldingen, films, audioopnamen, culturele artefacten en nog veel meer.” (Kuckartz 2012: 14)
In ons artikel over qualitativen und quantitativen onderzoeksmethoden hebben we al uitvoerig besproken dat beide onderzoekstypen zich onderscheiden qua doelstelling, uitvoering en opzet van het gehele onderzoek. Dit geldt ook voor gegevensanalyse, waarbij karakteristieke eigenschappen van kwalitatieve of kwantitatieve gegevens de selectie van de Auswertungsmethode beïnvloeden.
Zo worden kwalitatieve gegevens geanalyseerd
Kwalitatief onderzoek maakt gebruik van interpretatieve methoden van gegevensanalyse, waarmee gegevens bijv. uit een kwalitatieve bevraging, observatie of inhoudsanalyse in hun volle diepte kunnen worden vastgesteld. Daarbij zijn er in elk vakgebied talloze procedures en theorieën die worden gebruikt in het kader van kwalitatieve gegevensanalyse.
De meest voorkomende analysemethoden der kwalitatief onderzoek omvatten:
1. Codering of Categorisering:
Hierbij worden voor de belangrijkste begrippen van het onderzochte materiaal specifieke codes of categorieën toegewezen, om een vergelijkbaar overzicht van de kernconcepten te creëren. Complexe themagebieden kunnen aldus worden beperkt tot terugkerende elementen, om een basis voor verder statistisch onderzoek te vormen. Codering kan in alle vakgebieden worden toegepast, bijv. ook bij de transcriptie van een kwalitatief interview of als fundamenteel onderzoek in alle onderverzoekte themagebieden.
2. Kwalitatieve Inhoudsanalyse:
Een systematische analyse die interpretatie onder bepaalde, mogelijk uit de theorie afgeleide, criteria toestaat. Hiermee kunnen bijv. inhoudelijk onderbouwde mediaanalyses van specifieke medische aanbiedingen worden uitgevoerd.
3. Narratieve Analyse:
Thematische gedetailleerde tekstanalyse van subjectieve teksten (bijv. bij interviews van historisch relevante figuren), om regelmatigheid en terugkerende structuren in verhalen te identificeren. Deze analyse wordt vaak in biografieonderzoek gebruikt voor de reconstructie van gebeurtenissen.
4. Discourseanalyse:
Exakte Beobachtung einer Interaktion oder Konversation, bei der jedes kleine Detail – auch Mimik, Gestik und Dictus – festgehalten wird. Damit können z.B. politische Reden oder andere gesellschaftlich relevante Veranstaltungen und Bräuche analysiert werden.
Literaturtipp: Kuckartz, Udo (2012). Qualitative Inhaltsanalyse: Methoden, Praxis, Computerunterstützung. 2. Auflage. Weinheim und Basel: Beltz Juventa.
So werden quantitative Daten ausgewertet
Quantitative Forschung benutzt standardisierte Methoden der Datenauswertung z.B. aus einer quantitativen Befragung, Beobachtung oder Inhaltsanalyse, um an numerische Daten bzw. Zahlen zu kommen, die unter Anwendung von statistischen Verfahren komplexe gesellschaftliche Strukturen auf ihre wesentlichen Merkmale reduzieren und somit soziale Zusammenhänge messbar machen. Quantitative Datenanalyse setzt die Kenntnis sowie die richtige Anwendung statistischer Verfahren und die Fähigkeit zur Interpretation statistischer Ergebnisse voraus.
Statistische analysemethoden der kwantitatief onderzoek umfassen:
1. Deskriptive bzw. beschreibende Statistik:
Zusammenstellung und Darstellung von Daten, um eine anschauliche Informationsübersicht in Form von Tabellen und Grafiken zu ermöglichen.
2. Inferenzstatistik bzw. schließende Statistik:
Überprüfung von theoretischen Aussagen und Hypothesen mithilfe von statistischen Wahrscheinlichkeitsverfahren, um objektive Schlussfolgerungen über den untersuchten Gegenstand zu treffen.
In der Wissenschaft gehen die Forschenden davon aus, dass die Art der Daten zwangsweise ihren Auswertungstyp beeinflusst. Qualitative Daten können aber auch quantitativ erforscht werden – und umgekehrt. In der Praxis werden solche Methodenkombinationen oder “mixed-methods” sogar bevorzugt, um soziale Phänomene aus unterschiedlichen Perspektiven abzubilden.
Bei studentischen Arbeiten ist es immer sinnvoll und einfacher, sich auf eine passende – quantitative oder qualitative – Auswertungsart zu beschränken. Dennoch kann es natürlich sein, dass du bei z.B. einer quantitativen Umfrage durch offene Fragen auch qualitative Daten erhältst, die für bestimmte Aspekte deiner Forschung wichtig sind. In diesem Fall kannst du deine quantitative Datenauswertung um eine qualitative Codierung dieser Daten ergänzen.
Literaturtipp: Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, Methoden, Fallbeispiele, Tipps. 2 Auflage. Bern: Huber Verlag.

Quantitative Datenauswertung: Statistische Grundbegriffe verstehen und richtig anwenden
Wenn du im Rahmen deines studentischen Forschungsprojekts eine quantitative Forschung durchgeführt hast und in diesem Zuge bspw. eine standardisierte Online-Umfrage verwendet hast, ist die Auswertung mithilfe der beschreibenden und der schließenden Statistik die beste Möglichkeit zu wissenschaftlich fundierten Ergebnissen zu gelangen.
In diesem Statistik-Crashkurs wollen wir dir an einem konkreten Forschungsbeispiel die standardmäßig häufig verwendeten Prozesse und Begriffe der statistischen Datenauswertung veranschaulichen:
Die Datenauswertung mit SPSS oder einem anderen vergleichbaren Computerprogramm gilt allgemein als wissenschaftlich anerkannt. Besonders bei studentischen Arbeiten ist der Einsatz von SPSS und den Programmen R und Stata empfehlenswert und wird dir die Datenanalyse erleichtern.
Hinweis:
Im Rahmen einer kurzen Einführung können wir unmöglich die vielfältigen Möglichkeiten von SPSS im Detail besprechen, daher setzen wir die Kennung des Programms in diesem Beitrag voraus. Zur selbstständigen Einarbeitung in die Nutzung von SPSS empfehlen wir:
- Field, Andy (2009). Discovering statistics using SPSS. 3. Auflage. London: SAGE Publication.
Dieses englischsprachige Band bietet mit seinen 800 Seiten die wohl die umfassendste und dennoch leicht verständliche Einführung in die Arbeit mit SPSS. - Raithel, Jürgen (2008). Quantitative Forschung. Ein Praxiskurs. 2. Auflage. Wiesbaden: VS Verlag für Sozialwissenschaften.
Für eine kurze deutschsprachige Einführung siehe vor allem Kap. 7., S. 117-186: “Datenauswertung mit SPSS” sowie Kap. 9, S.197-200: “Nützliches im Umgang mit SPSS”.
Hinweis: Diese Übersicht soll vor allem verdeutlichen, warum es sich lohnt, statistische Kennwerte bei der Datenauswertung deiner Arbeit zu berücksichtigen. Einfachheitshalber berechnen wir alle unsere Werte mit SPSS. Auf mathematische Formeln zur Berechnung der einzelnen Werte können wir hier dagegen nicht eingehen. In den gängigen Statistik-Lehrbüchern werden die von uns angerissene Begriffe umfassender dargestellt.
Unser Literaturtipp: Quatember, Andreas (2008). Statistik ohne Angst vor Formeln. Das Studienbuch für Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Auflage. München: Pearson Studium.
Gratis enquête maken
Met empirio.ai maak je in enkele minuten een moderne online enquête — 100% gegevensbescherming uit Duitsland.
Gratis beginnenDeskriptive oder beschreibende Statistik: Zusammenfassung von Daten
“Die Deskriptivstatistik („descriptive statistics“, beschreibende Statistik) fasst die Stichprobendaten anhand von Stichprobenkennwerten (z. B. Mittelwerte, Prozentwerte etc.) zusammen und stellt diese bei Bedarf in Tabellen und Grafiken anschaulich dar.”
(Bortz/Doering 2016: 612)
In der deskriptiven Statistik werden deine gesammelten Daten bzw. Zahlen in tabellarischer Form, als eine Häufigkeitstabelle, ein Balkendiagramm oder ein Polygon erfasst (= als Prozente oder Mittelwerte beschrieben bzw. zusammengefasst). Das Ziel der deskriptiven Statistik ist es, ein klares Bild über die Verteilung verschiedener Werte zu bekommen.
Zwei einfache Beispiele, die aus den gesammelten Daten mit einem Programm wie Excel oder SPSS erstellt werden können:
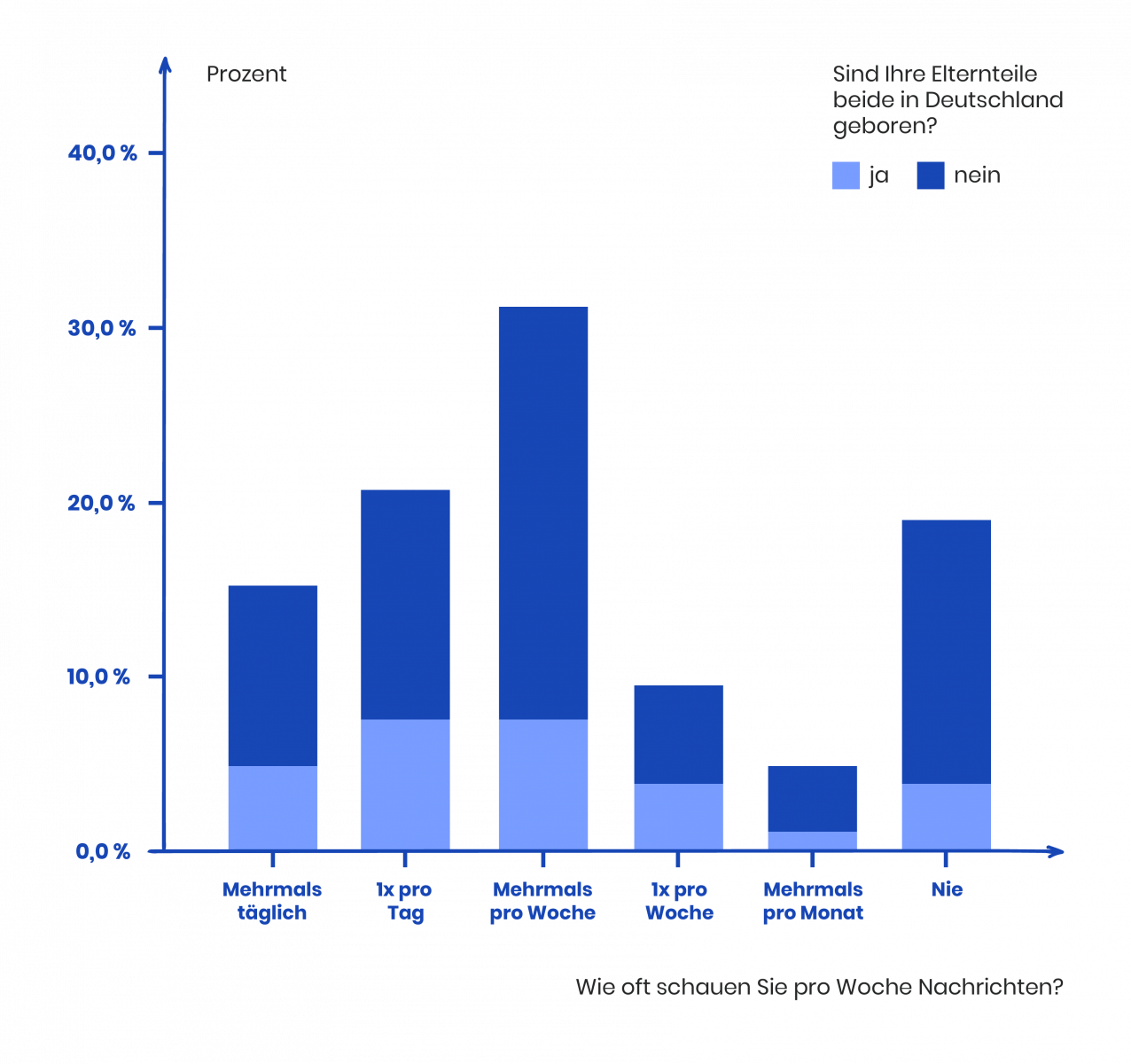
- Ein Balkendiagramm visualisiert die Häufigkeit des Fernsehkonsums bei Deutschen mit und ohne Migrationshintergrund. Wir können an diesem Diagramm ablesen, dass über 30 Prozent der Deutschen mehrmals pro Woche fernsehen – und zwar scheinbar unabhängig von ihrem Migrationshintergrund.
- Anhand eines Tortendiagramms können wir sehen, welche Nachrichtenprogramme innerhalb unserer Befragung bevorzugt werden: Tagesschau, RTL aktuell und Pro7 Newstime sind die drei meistgenutzten Fernsehprogramme.
Für einige Forschungsfragen können solche einfachen Darstellungen von Daten bereits aussagekräftige Schlüsse liefern. Dennoch sind für viele Zusammenhänge weitere statistische Kenngrößen bzw. Werte der deskriptiven Statistik notwendig, um wichtige Eigenschaften der vorhandenen Datenmenge zu erfassen und somit der Forschung mehr Validität zu verleihen.
1. Der Modalwert oder Modus
Der bei der Datenerhebung am häufigsten aufgetretene Messwert auf der Intervallskala.
Beispiel: Wir fragen 20 Personen (unsere Stichprobe n = 20): “Wie viele Stunden am Tag sehen Sie fern?” und bekommen folgende Antworten: 11 Personen: 2 Std., 3 Personen: 3 Std., 4 Personen: 1 Std., 2 Personen: 0 Std.
Unsere Ergebnisse sehen in Form einer Zahlenreihe wie folgt aus:
2 / 2 / 2 / 0 / 1 / 3 / 1 / 2 / 1 / 2 / 3 / 3 / 0 / 1 / 2 / 2 / 2 / 2 / 2 / 2 /
Unser Modalwert wäre in diesem Fall 2 (Stunden), also die am häufigsten auftretende Antwort bei unserer Umfrage. Gibt es mehrere Merkmalsausprägungen mit der gleichen maximalen Häufigkeit, ist in diesem Fall kein Modalwert vorhanden.
2. Das arithmetische Mittel oder Durchschnittswert
Das arithmetische Mittel gibt den Durchschnitt der Datenmenge an. Vereinfacht dargestellt, werden zur Berechnung des Durchschnitts alle Antworten summiert und durch die Anzahl der befragten Personen geteilt.
Beispiel: Bei unserer o.g. Zuschauerfrage hätten wir diese Rechnung:
(2+2+2+0+1+3+1+2+1+2+3+3+0+1+2+2+2+2+2+2+2 = 35):20 = 1,75 (Stunden) ist unser Durchschnittswert.
3. Der Median oder Zentralwert
Bei Daten, die in eine Reihenfolge gebracht werden können, ist es diejenige Merkmalsausprägung, die genau in der Mitte steht und die Messwerte in zwei gleich große Teile halbiert.
Beispiel: Bei unserer Fernsehfrage würde die Reihenfolge so aussehen:
0 / 0 / 1 / 1 / 1 / 1 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 2 / 3 / 3 / 3 /
Hier liegt die Mitte genau zwischen der 10. und der 11. Antwort, also in diesem Fall zwischen den fett markierten 2 und 2, der Median liegt also bei genau 2 (Stunden). Wichtig ist hier die Abgrenzung zum o.g. Durchschnittswert. Hätte bei unserer Umfrage eine Person angegeben, sie würde 8 statt 3 Stunden am Tag fernsehen, würde diese einzige atypische Antwort den Durchschnitt dennoch relativ stark anheben, während der Zentralwert unverändert bleibt.
4. Die Standardabweichung
Die Standardabweichung ist die durchschnittliche quadratische Abweichung vom Mittelwert. Dieser Kennwert verdeutlicht, wie stark einzelne Messwerte um den Mittelwert herum verteilt sind (= s.g. Streuung), d.h. wie weit die einzelnen Abweichungen von ihrem Durchschnitt (= dem oben berechneten arithmetischen Mittel) entfernt sind. Die Standardabweichung kann helfen, die erhobenen Daten aussagekräftiger zu interpretieren und große Ausreißer unter den Daten zu erkennen.
Beispiel: Bei der o.g. Fernsehfrage liegt die mit SPSS berechnete Standardabweichung bei 0,85. In unserer Forschungsarbeit können wir festhalten, dass unsere Befragten durchschnittlich 1,75 Stunden mit einer Abweichung von 0,85 Stunden täglich fernsehen.
5. Der Korrelationskoeffizient
Dieses Kriterium beschreibt den linearen Zusammenhang zwischen zwei Variablen, wenn zwei Merkmale (z.B. Fernsehnutzungsdauer als 1. Merkmal und das Alter der Befragten als 2. Merkmal) verglichen werden.
Liegt dein mit SPSS berechneter Korrelationskoeffizient zwischen 0,5 und 1 oder -0,5 und -1, dann ist deine Korrelation (= der Zusammenhang zwischen den beiden Merkmalen) statistisch hoch bzw. die Daten sind demnach positiv korreliert. Umgekehrt bedeutet es: Je kleiner der Korrelationskoeffizient, desto schwächer ist der Zusammenhang zwischen den untersuchten Merkmalen.
Beispiel: Wir lassen den Korrelationskoeffizient zwischen der Fernsehnutzung und dem Alter der Befragten berechnen (der liegt bei 0,9) und stellen fest, dass hier tatsächlich hohe positive Korrelation vorliegt. Der Zusammenhang zwischen der Fernsehnutzung und dem Alter der Befragten ist also statistisch als hoch einzustufen.
Die beschreibende Statistik ist im ersten Schritt deiner Datenanalyse notwendig, um die erhobenen empirischen Daten übersichtlich darzustellen und zu ordnen. Eine systematische Beschreibung der Daten mit den hier aufgeführten Kennwerten kann ebenfalls dafür benutzt werden, um mögliche Zusammenhänge und Abweichungen in deinem Datenmaterial zu erkennen.
Die mittels der deskriptiven Statistik getroffenen Aussagen sind jedoch noch nicht durch Fehlerwahrscheinlichkeiten abgesichert bzw. auf ihre Allgemeingültigkeit geprüft: Dies kann erst durch die Methoden der schließenden Statistik erfolgen.
Literaturtipp: Hug, Theo/Gerald Poscheschnik, unter Mitarbeit von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. Über die Planung und Umsetzung von Projekten im Studium. Konstanz: UVK ➔ siehe vor allem Kap. V., S. 151 - 190: “Datenauswertung”.
Inferenzstatistik oder schließende Statistik: Überprüfung von Hypothesen
“Die Inferenzstatistik („inferential statistics“, schließende Statistik) schließt anhand von Stichprobendaten auf Populationsverhältnisse. Dabei wird zum einen die Ausprägung einzelner Variablen in der Population geschätzt (Methoden der statistischen Parameterschätzung) und zum anderen werden Hypothesen zu Relationen zwischen Variablen in der Population geprüft (Methoden der statistischen Hypothesenprüfung).”
(Bortz/Doering 2016: 612)
Schließende Statistik oder Inferenzstatistik verwendet Methoden der Wahrscheinlichkeitstheorie, um fundierte Entscheidungen darüber zu treffen, ob erhaltene Ergebnisse die aufgestellten Hypothesen stützen oder auf zufällige Abweichungen zurückzuführen sind. Außerdem kann mithilfe der Inferenzstatistik festgestellt werden, inwieweit die vorliegende Studie als repräsentativ gelten kann.
Damit kannst du grundsätzlich überprüfen, ob deine empirischen Befunde bei der Datenerhebung zufällig durch die Stichprobe entstanden sind oder ob es sich dabei um nachweisliche Gesetzmäßigkeiten, also eine statistische Signifikanz handelt. Die statistische Signifikanz gibt also grundsätzlich an, mit welcher Wahrscheinlichkeit die untersuchte Hypothese tatsächlich zutrifft.
Beispiel: Zu Beginn unserer Forschungsarbeit haben wir die Hypothese aufgestellt, dass der häufige Nachrichtenkonsum eine negative Auswirkung auf die mentale Befindlichkeit der deutschen Fernsehzuschauer hat. Anhand unserer ersten deskriptiven Auswertungen ist bereits die erste Tendenz zu erkennen, dass diese Aussage korrekt sein könnte (40 Prozent der Personen haben die entsprechende Antwort ausgewählt). Im zweiten Schritt müssen wir nun ermitteln, ob tatsächliche Gesetzmäßigkeiten (bzw. die statistische Signifikanz) nachgewiesen werden können.
Das Ergebnis einer statistischen Untersuchung gilt generell erst dann als signifikant, wenn es mit einer bestimmten Wahrscheinlichkeit nicht zufällig ist.
Das wichtigste Verfahren in der Inferenzstatistik ist der Hypothesentest, der die Mittelwerte von Verteilungen vergleicht und Aussagen darüber zulässt, ob die anfangs aufgestellten Hypothesen signifikant anzunehmen oder abzulehnen sind.
Grundlagen zur Durchführung eines Hypothesentests
Mithilfe eines Hypothesentest kannst du also deine Arbeitshypothese, die du zu Anfang deiner Arbeit aufgestellt hast, anhand der erhobenen Daten überprüfen. Anzumerken ist an dieser Stelle, dass Hypothesentests etwas mehr statistisches Verständnis erfordern und nicht in der gesamten Bandbreite in unserer kurzen Einführung abgedeckt werden können.
Zur selbstständigen und tiefergehenden Beschäftigung mit dem Hypothesentest ist dieser Literaturtipp wärmstens zu empfehlen: Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
Für einen ersten Eindruck wollen wir vielmehr andeuten, wie du grundsätzlich bei einem Hypothesentest vorgehen kannst:
1. Nullhypothese und Alternativhypothese festlegen
Der Grundgedanke beim Hypothesentest ist, dass wir eigentlich das Gegenteil unserer Hypothese, die so genannte Nullhypothese (H0) widerlegen müssen (bzw. Nullhypothese widerlegen = ursprüngliche Hypothese eindeutig bestätigen). Forschende gehen so lange davon aus, dass die Nullhypothese korrekt ist, bis sie sich eben im Test als falsch erwiesen hat. Findet man aufgrund der gesammelten Daten den Beweis, dass die Nullhypothese falsch ist, dann muss deine Arbeits- bzw. die Alternativhypothese (H1) wahr sein.
Beispiel: Deine aufgestellte Hypothese zum Anfang deiner Arbeit: Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit. Nullhypothese (H0): Zwischen häufigem Nachrichtenkonsum und der mentalen Befindlichkeit gibt es keinen Zusammenhang. Alternativhypothese (H1): Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit.
2. Passenden Test wählen
Abhängig von der Fragestellung gibt es verschiedene Arten der statistischen Tests. Dabei unterscheidet man zwischen parametrischen Tests (z.B. wie der Chi-Quadrat-Test, bei dem Streuparameter von zwei Stichproben miteinander verglichen werden) und Verteilungsanpassungstests bzw. nicht-parametrischen Tests (z.B. t-Test oder F-Test, bei denen die Daten auf ihre Verteilung überprüft werden).
Beispiel: Um die oben aufgeführte Hypothese zu testen, müssen wir die intervallskalierte Variable „Befindlichkeit“ und die ordinalskalierte Variable „Häufigkeit des Nachrichtenkonsums“ auf einen möglichen Zusammenhang untersuchen. Wird der Zusammenhang bestätigt, kann die H0 abgelehnt werden. In unserem Fall kommt die Rangkorrelation nach Spearman in Frage, weil er intervall- und ordinalskalierte Variablen am besten testen kann.
3. Signifikanzwert bzw. p-Wert berechnen
Der p-Wert gibt die Wahrscheinlichkeit an, mit der man das aus den Daten vorliegende Testergebnis (berechnet mit der Software SPSS) erhält, sollte die Nullhypothese richtig sein. Ab einem bestimmten p-Wert werden die Ergebnisse als statistisch signifikant bezeichnet. Ist der p-Wert klein genug, gilt die Ablehnung der Nullhypothese und dementsprechend die Annahme der Alternativhypothese als statistisch gerechtfertigt bzw. das Ergebnis der Stichprobe gilt als statistisch signifikant.
In vielen statistischen Untersuchungen, insbesondere in den Sozial- und Geisteswissenschaften, wird traditionell ein Signifikanzniveau von 5% angenommen, also ist der p-Wert = 0,05 (oder kleiner!), gilt die Nullhypothese als widerlegt.
Beispiel: Unter der Durchführung des einseitigen Spearman’s Rho-Hypothesentests liegt der berechnete Signifikanzwert bei unserer Studie bei 0,01 % (also niedriger als der Schwellwert 0,05 %), daher können wir die Nullhypothese H0 endgültig widerlegen.
Testergebnisse:
- Nullhypothese (H0): Zwischen häufigem Nachrichtenkonsum und der mentalen Befindlichkeit gibt es keinen Zusammenhang. = widerlegt
- Alternativhypothese (H1): Häufiger Nachrichtenkonsum hat eine negative Auswirkung auf die mentale Befindlichkeit. = bestätigt
Damit haben wir bei mithilfe der Inferenzstatistik bewiesen, dass wir innerhalb unserer Studie von einem signifikanten Zusammenhang zwischen der Häufigkeit des Nachrichtenkonsums und schlechterer mentaler Befindlichkeit der Deutschen sprechen können.
Abschließend werden diese Ergebnisse zusammen mit den deskriptiven Auswertungen in der Arbeit verschriftlicht. Wie du diese in deine Abschlussarbeit optimal einbauen kannst, erfährst du im nächsten Kapitel.

Die Datenauswertung in die Abschlussarbeit integrieren
Mit der Datenanalyse startet die unmittelbare Auswertung deiner Forschungsdaten, daher gehört dieser Abschnitt zum zentralen Bestandteil deiner Abschlussarbeit. Bei der Verschriftlichung ist es ebenfalls sinnvoll, diesen Schritt direkt nach der Datenerhebung anzugehen:
1. Einleitung
1.1. Forschungsinteresse: Einführung in die Thematik
1.2. Zielsetzung: Formulierung der Forschungsfrage
2. Theorie: Stand der Forschung
3. Forschungsdesign
3.1. Bildung der Hypothesen
3.2. Wahl der onderzoeksmethode, z.B. quantitative Befragung
3.3. Stichprobe festlegen
3.4. Definition und Festlegung der untersuchten Variablen und Merkmale
3.5. Fragenkatalog
4. Datenerhebung: Standardisierte Online-Umfrage
5. Datenauswertung
5.1. Deskriptive Darstellung der Ergebnisse
5.2 Prüfung der Hypothesen mithilfe der Inferenzstatistik
6. Ergebnisse und Erkenntnisse
7. Reflektion der eigenen Vorgehensweise
8. Fazit
Weiterführende Literatur:
Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, Methoden, Fallbeispiele, Tipps. 2 Auflage. Bern: Huber Verlag.
Bortz, Jürgen/Nicola Döring (2016). onderzoeksmethoden und Evaluation für Sozialwissenschaftler. 5. Auflage. Berlin: Springer Verlag.
Field, Andy (2009). Discovering statistics using SPSS. 3. Auflage. London: SAGE Publication.
Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
Hug, Theo/Gerald Poscheschnik, unter Mitarbeit von Bernd Lederer und Anton Perzy (2010). Empirisch Forschen. Über die Planung und Umsetzung von Projekten im Studium. Konstanz: UVK
Hunziker, Alexander W. (2013). Spass am wissenschaftlichen Arbeiten. So schreiben Sie eine gute Semester-, Bachelor- und Masterarbeit. 5. Auflage. Zürich: SKV.
Kuckartz, Udo (2012). Qualitative Inhaltsanalyse: Methoden, Praxis, Computerunterstützung. 2. Auflage. Weinheim und Basel: Beltz Juventa.
Raithel, Jürgen (2008). Quantitative Forschung. Ein Praxiskurs. 2. Auflage. Wiesbaden: VS Verlag für Sozialwissenschaften.
Quatember, Andreas (2008). Statistik ohne Angst vor Formeln. Das Studienbuch für Wirtschafts- und Sozialwissenschaftler. 2. aktualisierte Auflage. München: Pearson Studium.
Urban, Klaus (1996). Statistik. Einführung in die statistische Methodenlehre. 4. Auflage. München/Wien: De Gruyter Oldenbourg
Gratis enquête maken
Met empirio.ai maak je in enkele minuten een moderne online enquête — 100% gegevensbescherming uit Duitsland.
Gratis beginnen