In den seltensten Fällen ist es bei einer empirique Étude möglich, alle in der Question de recherche umfassten Personnes oder Sachverhalte tatsächlich zu berücksichtigen. Führst du für deine Seminar- oder Mémoire de fin d'études eine quantitative Online-Enquête durch, ist eine wissenschaftlich fundierte Auswahl der zu untersuchten Personnes – die so genannte Bildung einer Échantillon – deine erste Herausforderung.
Die Größe der Échantillon steht dabei im unmittelbaren Zusammenhang mit den Zielen und Fragestellungen deiner Recherche. Wenn du die eigenen Ergebnisse auf eine allgemeingültige Gesamtheit übertragen möchtest, sind eine ausreichend große Échantillon sowie die daraus resultierende höchstmögliche Repräsentativität entsprechend wichtig. Doch auch die Recherche mit kleinen Fallzahlen bzw. mit einem kleineren Personenkreis im Rahmen deiner studentischen Arbeit ist keinesfalls unbrauchbar oder ungültig. Vielmehr kommt es darauf an, wie deine Objectifs de recherche formuliert sind und ob du dich bei dem Umgang mit deiner Methode angemessen auseinandergesetzt hast. In diesem Beitrag zeigen wir, wie du die richtige Stichprobengröße für deine Enquête en ligne findest und was du dabei beachten musst.
Créer un sondage gratuitement
Avec empirio.ai, vous créez un sondage en ligne moderne en quelques minutes — protection des données à 100 % depuis l'Allemagne.
Commencer gratuitementDer Grundstein einer empirique Collecte de données: Die Bedeutung einer Échantillon verstehen
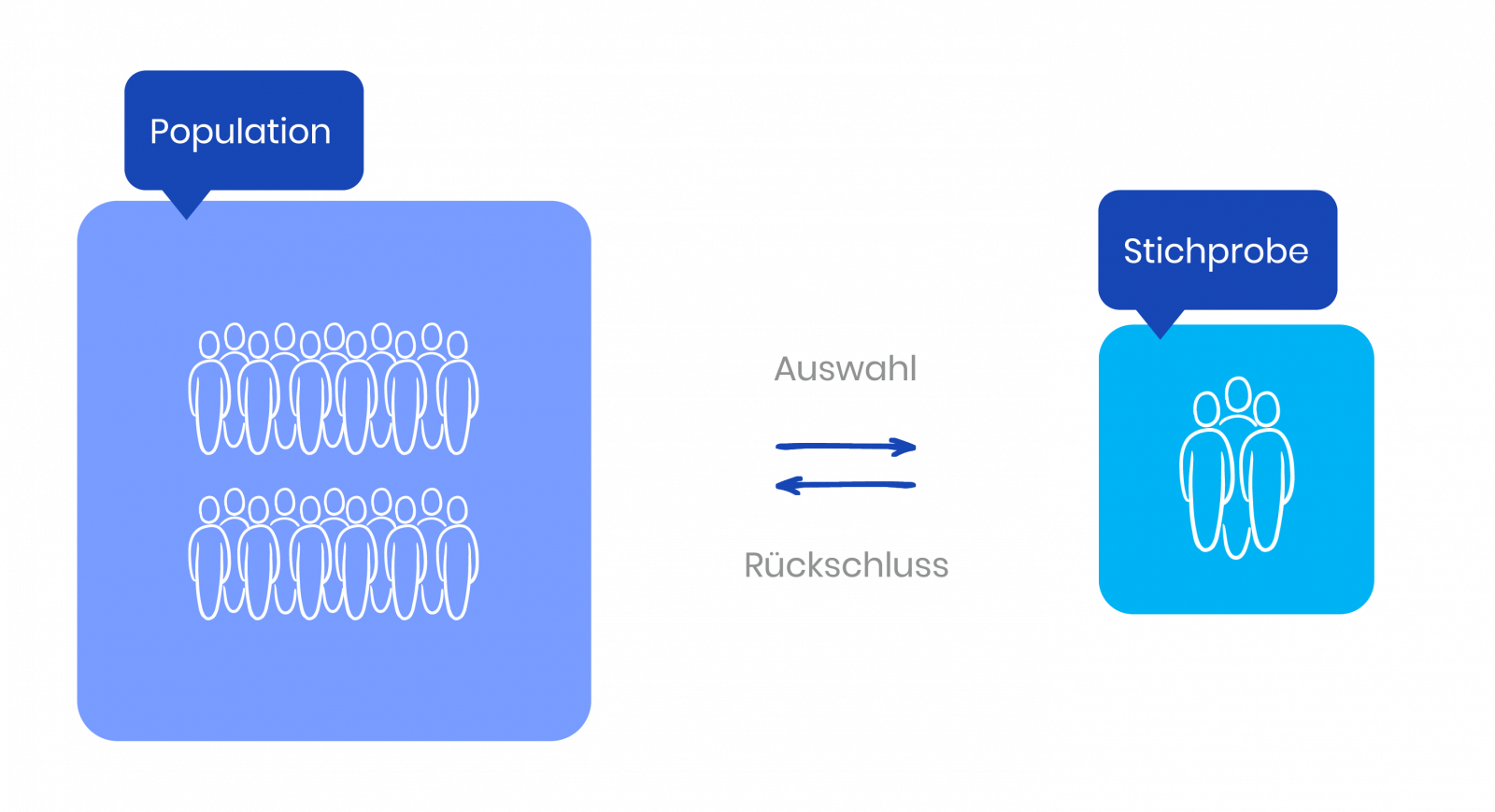
Bei der Durchführung einer quantitativen Enquête ist notwendig im Vorfeld zu definieren, über welche Personnes oder Personengruppen überhaupt geforscht werden soll. Im theoretischen Idealfall müssten die Forschenden alle Menschen aus dieser festgelegten Gruppe (= Population bzw. die Population totale) befragen, um exakte Ergebnisse über den untersuchten Gegenstand zu bekommen.
Logischerweise ist dies in der Praxis in den meisten Fällen schlicht unmöglich. Vor allem dann, wenn spezifische Aussagen über eine große Population wie etwa die deutsche Bevölkerung getroffen werden sollen. Stattdessen kann in der Wissenschaft stets nur eine kleine Sous-ensemble der Population (= Échantillon) untersucht werden, um zu Aussagen über die gesamte festgelegte Gruppe zu gelangen: Darauf basiert das Grundprinzip der Échantillon.
Selbst bei einer großangelegten Sondage électoral kann nur eine bestimmte Anzahl von Wählern (z.B. 2000 Personnes) aus ca. 60 Millionen Électeurs inscrits in Deutschland zu ihrer möglichen Abstimmung berücksichtigt werden. Das bedeutet aber nicht, dass die Forschenden ihre Studienteilnehmer beliebig auswählen.
Damit die Ergebnisse einer solchen Enquête trotzdem repräsentativ sind (= die untersuchte Population so genau wie möglich abbilden), wird im Vorfeld ein statistisches Procédures de sélection zur Bildung einer Échantillon durchgeführt. Dabei sollen solche Studienteilnehmer bestimmt werden, die ihre gesamte Gruppe entsprechend repräsentieren.
Wird das Procédure d'échantillonnage nicht sorgfältig durchgeführt, können die gesammelten Daten fehlerhaft sein und zu falschen Erkenntnissen führen.
Bei einer bekannten Sondage während der amerikanischen Präsidentschaftswahl im Jahre 1936 war das Ergebnis durch eine falsch gewählte Échantillon verzerrt. Dabei hatte eine amerikanische Zeitschrift aufgrund von ca. 2 Millionen Fragebögen den Sieg des republikanischen Kandidaten Landon vorhergesagt – und lag damit fast um 20 Prozent daneben.
Warum kam die Enquête zu einem solch falschen Ergebnis, obwohl die Échantillon so groß ausfiel?
- Das Problem lag darin, dass der Questionnaire nur an Personnes aus einer Base de données automobile geschickt wurde. Die ausgewählte Échantillon umfasste also nur diejenigen, die über ein Auto verfügten und somit in dieser Zeit ein deutlich überdurchschnittliches Einkommen sowie eher konservative politische Haltung hatten. Die Enquête war also keineswegs für die gesamte Bevölkerungsgruppe (= Wähler aus allen sociales couches) repräsentativ.
- In diesem Fall ist die Repräsentativität ein wichtiger Bestandteil von angestrebten Erkenntnissen und daher für eine valide Recherche unabdingbar! In der modernen Forschungspraxis müssen aber nicht alle Studien repräsentativ sein, um trotzdem eine gültige Validität aufweisen zu können. Die Wichtigkeit der Repräsentativität hängt immer von konkreten Forschungszielen ab!
Das Wahlbeispiel aus:
Balzert, Helmut et al. (2011). Travail scientifique Arbeiten. 2 édition. Berlin/Dortmund: Springer Campus
➔ siehe vor allem Chapitre 3.5., S. 28-29: “Validität”
Literaturtipp:
Raithel, Jürgen (2008). quantitative Recherche. Ein Praxiskurs. 2. édition. Wiesbaden: VS Verlag für Sciences sociales.
➔ siehe vor allem Chapitre 4.6., S.54-62: “Échantillons/Procédures de sélection”
Unsere Step-By-Step Anleitung: Eine wissenschaftlich fundierte Échantillon bilden
Unabhängig von der Größe deiner Étude, kannst du deine Échantillon grundsätzlich mit nur drei Schritten bestimmen. An einem konkreten Beispiel zeigen wir, wie du dabei vorgehen kannst.
Annahmen für unser Beispiel:
- Forschungsinteresse: Nehmen wir an, du machst eine Studie über die Fernsehnutzung in Deutschland. Du möchtest herausfinden, welche Sender derzeit bei der deutschen Bevölkerung am beliebtesten sind und wieviel Zeit Menschen heutzutage vor dem Fernseher verbringen.
- Forschungsmethode: Eine quantitative Enquête en ligne ist für dich die einfachste und effektivste Methode der Collecte de données. Im Gegensatz zu einer schriftlichen oder mündlichen Enquête kannst du so in kürzester Zeit sowie äußerst budgetfreundlich eine große Anzahl an Personnes erreichen.
Schritt 1: Dénombrement complet ou partiel aufgrund der Population totale bestimmen
“Eine Population totale ist die Menge von Objekten, über die Aussagen getroffen werden sollen.” (Brosius et al 2009: 71)
Bevor du mit der unmittelbaren Stichprobenbildung beginnst, musst du im ersten Schritt festlegen, welche Untersuchungsobjekte du in deiner Recherche überhaupt berücksichtigen möchtest oder kannst.
Zunächst ist dabei die Population totale zu beachten: Dabei ist die gesamte Gruppe der zu untersuchten Personnes gemeint, die über ein oder mehrere gemeinsame Merkmale verfügen. In der Statistik wird die Population totale mit dem Wert “N” gekennzeichnet. In unserem Beispiel wären es alle volljährigen Personnes, die in Deutschland leben und über einen Fernsehanschluss verfügen.
Wenn du alle Personnes aus der Population totale untersuchen kannst, was aus statistischer Sicht der Idealfall wäre, dann würdest du eine Vollerhebung vornehmen. Vollerhebungen werden manchmal in der Meinungsforschung durchgeführt, wenn die Population totale relativ klein ist.
Würdest du dich bei deiner Recherche dafür interessieren, welches Fernsehverhalten die Vorsitzenden der Medienanstalten in Deutschland haben, könntest du die theoretisch alle befragen, da deine Population totale nur ca. 100 Personnes umfasst. Dafür müsstest du allerdings alle diese Personnes tatsächlich erreichen und zu einer Sondage motivieren. Selbst in großen Projekten ist diese Form der Étude zeitintensiv und kompliziert.
Wenn die Population totale entweder zu groß ist oder nicht eindeutig definierbar, wird eine verkleinerte strukturgleiche Sous-ensemble der Population totale mithilfe der Stichprobenziehung untersucht und entsprechend eine Teilerhebung vorgenommen. In den meisten Forschungsprojekten ist dies die einzige Möglichkeit zur Collecte de données. In der Statistik werden diese Teilelemente der Population totale mit dem Wert “n” gekennzeichnet.
In unserem Forschungsbeispiel ist die Anzahl aller Fernsehzuschauer in Deutschland einfach zu groß. Alleine aufgrund dessen wäre es unmöglich, eine Vollerhebung in Bezug auf ihr Fernsehverhalten durchzuführen. Eine Teilerhebung ist also die einzige Möglichkeit, dein Forschungsvorhaben umzusetzen.
Literaturtipp:
Brosius, Hans-Bernd et al. (2009). Methoden der empirique Kommunikationsforschung. Eine Einführung. 5 édition. Wiesbaden: VS Verlag für Sciences sociales.
➔ siehe vor allem Chapitre 4, S.71-91: “Procédures de sélection”
Schritt 2: Type d'échantillon auswählen
“Eine Échantillon stellt eine Sous-ensemble aller Untersuchungseinheiten dar, die die untersuchungsrelevanten Eigenschaften der Population totale möglichst genau abbilden.” (Bortz 1993: 84, zitiert nach Raithel 2008: 54).
Die meisten stichprobenbasierten Études haben das Ziel, von Aussagen über die gewählte Sous-ensemble zu Erkenntnissen über die gesamte Population totale bzw. Population zu gelangen. Eine solche inhaltliche Übertragung wird in der Recherche Repräsentationsschluss genannt und ist nur dann gültig, wenn die Elemente aus der Population totale in der Sous-ensemble in der gleichen Zusammensetzung vertreten sind. Dabei muss die gezogene Échantillon die Population totale möglichst genau abbilden.
Grundsätzlich wird zwischen drei Gruppen von Procédure d'échantillonnage unterschieden:
- Willkürliche Auswahl: Diese unkontrolliert gebildete Échantillon wird manchmal bei psychologischen Experimenten mit freiwilligen Probanden gemacht und erlaubt keinerlei Aussagen über die Population totale. Häufig wird dieses Verfahren entweder mit einem weiteren kombiniert, um zu aussagekräftigen Ergebnissen zu kommen – oder sie strebt ohnehin aufgrund der Question de recherche keine Repräsentativität an.
- Bewusste Auswahl: Diese Auswahl nach spezifischen Kriterien ist dann sinnvoll, wenn extreme Fälle untersucht werden sollen bzw. wenn die zu untersuchenden Merkmale in der Population totale stark unterschiedlich vorhanden sind. Auch hier ist mit gewisser Verzerrung der Repräsentativität zu rechnen.
- Zufallsauswahl oder Wahrscheinlichkeitsauswahl: Bei dieser Auswahl entscheidet ein statistischer Zufallsprozess darüber, welche Merkmalsträger aus der Population totale in die Échantillon aufgenommen werden. Die Zufallsauswahl ist das einzige Procédure d'échantillonnage, das die Repräsentation gewährleisten kann bzw. in ihrem Ansatz dafür sorgt, dass alle Personnes der Population totale die gleiche Chance haben, bei der Recherche berücksichtigt zu werden.
Dabei sind folgende Varianten der Zufallsstichproben weit verbreitet:
- Einfache Zufallsstichprobe: Elemente oder Personnes der Population totale werden ähnlich wie in einer Lotterie zufällig gezogen. Dabei hat jedes Element der Population totale die gleiche Chance, mithilfe von verschiedenen systematischen Zufallsverfahren (z.B. durch einen Zufallsgenerator) gezogen zu werden.
Eine solche Échantillon ist sehr genau und ist hinsichtlich aller Merkmale der Population repräsentativ. Allerdings müssen die Forschenden dafür sorgen, dass wirklich jedes Element aus der Population totale für die Ziehung zugänglich ist – das ist in der Praxis nicht immer einfach.
- Geschichtete Zufallsstichprobe: Elemente bzw. Personnes der Population totale werden zunächst nach einem bestimmten Merkmal aufgeteilt (z.B. nach dem Alter der Fernsehzuschauer). Die Zufallsstichprobe wird zuerst aus der jeweiligen Gruppe (= aus der ”Schicht”) gezogen. Im nächsten Schritt werden Échantillons aus diesen verschiedenen couches zu einer Sous-ensemble zusammengefügt.
Um die bestmögliche Stichprobenverteilung zu gewährleisten, wird dabei berücksichtigt, wie groß die jeweilige Gruppe in der Population totale vorhanden ist (z.B., wenn es doppelt so viele über 50-Jährige als unter 20-Jährigen Fernsehzuschauer gibt, werden entsprechend doppelt so viele 50-Jährigen im Vergleich zu unter 20-Jährigen in die gesamte Sous-ensemble aufgenommen).
In der Forschungspraxis ist dieses Verfahren sehr beliebt, da sichergestellt werden kann, dass gewisse Teile der Population in Bezug auf das geschichtete Merkmal nicht unter- oder überrepräsentiert sind.
- Klumpenstichprobe: Aus Elementen bzw. Personnes der Population totale werden zunächst größere Einheiten (=”Klumpen”) gebildet (z.B. ein Haushalt, der sich aus mehreren Fernsehzuschauern zusammensetzt, könnte als ein Klumpen definiert werden), dann wird aus den vorhandenen Klumpen zufällig eine Einheit ausgewählt und vollständig untersucht.
Die Repräsentativität dieser Stichprobenziehung hängt jedoch immer davon ab, wie gut die Forschenden die Kriterien zur Bildung der Einheiten bzw. der Klumpen festgelegt haben.
In unserem Forschungsbeispiel wirst du mithilfe der einfachen Zufallsstichprobe vermutlich am einfachsten und effektivsten zu den angestrebten Daten bezüglich der Fernsehnutzung der Deutschen kommen.
Literaturtipp:
Beller, Sieghard. (2016). Empirisch forschen lernen. Konzepte, Methoden, Fallbeispiele, Tipps. 2 édition. Bern: Huber Verlag.
➔ siehe vor allem Chapitre 4, S.85 - 98: “Repräsentativität und Précision von Échantillons”
- Das stellt zwar die Verallgemeinerung bzw. die Repräsentativität deiner Erkenntnisse in Frage, allerdings sind studentische Befunde ohnehin selten repräsentativ – auch deinen Prüfern ist es bewusst!
- Möchtest du jedoch eine möglichst repräsentative Studie aufstellen, musst du dies bereits bei deinem Forschungsinteresse berücksichtigen und eine kleinere Population totale in Betracht ziehen. Statt das Fernsehverhalten der gesamten deutschen Bevölkerung untersuchen zu wollen, könntest du dich stattdessen mit den Fernsehgewohnheiten von Studierenden der Medienwissenschaft an der Universität Hamburg befassen. Eine kleinere Échantillon kann mit weniger Aufwand präzisere Ergebnisse liefern.
Schritt 3: Stichprobengröße und ihre Précision berechnen
“Die empirique Sozialforschung nimmt in der Regel eine fünfprozentige Irrtumswahrscheinlichkeit in Kauf. Ergebnisse, die sie produziert, sind mit diesem Zufallsfehler behaftet.” (Brosius et al 2009: 77)
Zur Bestimmung deiner Échantillon bleibt im letzten Schritt noch auszurechnen, welche Stichprobengröße grundsätzlich notwendig ist, damit deine Recherche als repräsentativ gilt. Mithilfe der Inferenzstatistik werden dabei spezifische Werte ausgerechnet, um die in deiner Recherche erhaltenen Daten auf zufällige Abweichungen zu überprüfen. Daraus kannst du dann die benötigte Stichprobengröße ableiten.
In diesem Zusammenhang musst du zunächst diese Begriffe und Werte für deine Recherche definieren:
- Deine Population totale bzw. die Populationsgröße (N)
Grundlegende Frage: Über welche Bevölkerungsgruppe möchtest du überhaupt Aussagen treffen? Die gesamte Gruppe der zu untersuchten Personnes.
Beispiel: Bei unserer Fernsehforschung suchen wir also nach allen Menschen in Deutschland, die zu Hause fernzusehen können. Laut der aktuellen Studie der Arbeitsgemeinschaft Fernsehforschung besitzen im Schnitt rund ca. 64 Millionen der Deutschen einen Fernseher. Diese können wir zu unserer Population totale zählen.
- Irrtumswahrscheinlichkeit (oder Fehlerspanne) (e)
Grundlegende Fragen: Wie nah liegen deine Sondage-Ergebnisse an den tatsächlichen Ergebnissen in der gesamten Population (wenn man diese erheben könnte)? Was ist die mögliche Fehlerquote, die du in Kauf nehmen musst bzw. mit der du rechnen kannst?
Ein Prozentsatz, der angibt, wie präzise das Hochrechnen der Échantillons auf deine Population totale ausfallen wird. In der Recherche wird angenommen, dass selbst die sorgfältigste Échantillon nicht garantieren kann, das gesuchte Merkmal der Population totale tatsächlich zu finden. Mit einer gewissen Fehlerquote müssen die Forschenden einfach rechnen.
Üblicherweise liegt die erwartete Irrtumswahrscheinlichkeit in den meisten Forschungsprojekten bei 5 Prozent (= 0,05 als Wert), wobei jede Fehlerspanne zwischen 1 und 10 Prozent möglich ist. Darüber hinaus gilt die Studie als unzuverlässig. Du kannst selbst entscheiden, wie genau deine Ergebnisse ausfallen sollen bzw. wie viele Fehler du in deiner Recherche zulassen möchtest.
Beispiel: Hast du in deiner Recherche eine Fehlerspanne von 5 Prozent festgelegt, so haben deine Ergebnisse immer eine Précision von +/- 5 Prozent. Geben 30 Prozent der Teilnehmenden (= die gewählte Échantillon) bei deiner Enquête an, täglich zwei Stunden lang fernzusehen, dann wäre deine Erkenntnis aufgrund der aufgestellten Irrtumswahrscheinlichkeit vielmehr, dass höchstwahrscheinlich zwischen 25 (30 Prozent - 5) und 35 Prozent (30 Prozent +5) der deutschen Fernsehzuschauer (= deine Population totale) tatsächlich dieser Tätigkeit in diesem Umfang nachgehen.
- Konfidenzniveau (oder Konfidenzintervall)
Grundlegende Frage: Wie sicher möchtest du bei deiner Studie sein (in Prozentzahlen), dass deine Ergebnisse tatsächlich die festgelegte Population totale abbilden?
Das Konfidenzniveau misst die Wahrscheinlichkeit bzw. den Grad der Précision, mit der die Échantillon deine Population totale unter Berücksichtigung der zuvor gewählten Fehlerspanne abbildet. Ein Konfidenzniveau von 95 Prozent ist am geläufigsten, wobei auch Werte zwischen 80 und 99 Prozent in der Praxis verwendet werden. Während die Irrtumswahrscheinlichkeit angibt, welche Fehlerspanne bei den Antworten möglich ist, drückt das Konfidenzniveau in Prozenten aus, wie sicher du dir bist, dass deine Ergebnisse die gewählte Gesamtpopulation repräsentieren.
Beispiel: Entscheidest du dich für das Konfidenzniveau von 95 Prozent (mit der vorher festgelegten Irrtumswahrscheinlichkeit von 5 Prozent), so könntest du in unserer Fernsehforschung mit einer Zuversichtlichkeit von 95 Prozent sagen, dass zwischen 25 und 35 Prozent der Deutschen tatsächlich zwei Stunden lang täglich fernsehen.
- Z-Wert
Grundlegende Fragen: Wie ist die Differenz zwischen deinen Ergebnissen und dem normalen Mittelwert (also den üblichen Durchschnittsergebnissen) bei der Population?
Ausgehend aus dem Konfidenzniveau wird der sogenannte Z-Wert automatisch festgelegt. Dieser zeigt den in der Wissenschaft üblichen Mittelwert an, mit dem Standardabweichungen in der Population gemessen werden. Der standardisierte Z-Wert kann zwar auch berechnet werden, für die typischen Konfidenzen kann dieser jedoch in Z-Wert-Tabellen (online oder in allen gängigen Statistik-Büchern) nachgeschlagen werden.
Beispiel: Bleiben wir beim Konfidenzniveau von 95 Prozent, so liegt der zum Berechnen der Échantillon benötigte Z-Wert bei 1,96. Typischerweise kannst du in deiner studentischen Arbeit zur Ermittlung der Stichprobengröße einfach mit dem Wert aus der Tabelle arbeiten, der deiner zuvor gewählten Konfidenz entspricht. Weitere Erläuterungen sind in der Regel nicht notwendig.
Unsere kleine Übersicht zeigt die Z-Werte für die gängigsten Konfidenzintervalle:
Konfidenzniveau bzw. -intervall
Z-Wert
99%
2,58
95%
1,96
90%
1,65
85%
1,44
80%
1,28
- Standardabweichung (p)
Grundlegende Fragen: Denkst du, dass die Befragten bei deiner Sondage alle eher gleiche Antworten geben werden – oder umgekehrt extrem unterschiedliche? Wieviel Antwort-Vielfalt erwartest du?
Dieser Wert zeigt die durchschnittliche Entfernung aller gemessenen Ausprägungen eines Merkmals von seinem Durchschnitt bzw. wie viel Varianz bei deiner Enquête zustande kommen wird. Anders gesagt: Die Standardabweichung gibt an, wieviel Variation du unter deinen Antworten erwartest. Die Standardabweichung ist im Vorfeld, also bevor du deine Sondage machst, so gut wie unmöglich zu bestimmen und wird von den meisten Forschenden auf höchstmögliche 50 Prozent (bzw. auf den Wert von 0,5) gesetzt. Studierende können in der Regel ebenfalls mit diesem Wert arbeiten, ohne dass sie die Standardabweichung anderweitig begründen müssen.
Aus diesen Werten (N=64.000.000, z=1,96,e=0,05 und p=0,5) kannst du nun mithilfe einer statistischen Formel die Mindestgröße einer Échantillon berechnen: Damit unsere Fernsehforschung repräsentativ ausfällt, müssten mindestens 385 Personnes aus der Population totale an unserer Enquête en ligne teilnehmen.
In unserem Beispiel kommen wir so zu dieser Stichprobengröße:
Literaturtipp und (von uns vereinfachte und minimal angepasste) Formel angelehnt an ausführliche Berechnungen aus:
Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
➔ vor allem Chapitre 4., S. 43 - 65: “Intervallschätzung” und Chapitre 5., S. 67 - 75: “Notwendiger Stichprobenumfang” erklären noch einmal ganz ausführlich, wie alle oben genannten Werte mathematisch berechnet werden können.
In unserem Beitrag arbeiten wir einfachheitshalber mit bereits berechneten “Z”- (bei Holland/Scharnbacher auch als “t” gekennzeichnet, in anderer Literatur ist “Z” aber gängiger),”e”- und “p”-Werten. Falls die Anforderung in deinem Fach die selbstständige Berechnung umfasst, eignet sich dieses Band sehr gut als Nachschlagewerk.
Abhängig von den festgelegten Parametern, die wir oben beschrieben haben, kann deine Stichprobengröße selbst bei der gleichen Population totale (64.000.000) variieren:
Stichprobengröße - abhängig von Irrtumswahrscheinlichkeit und Konfidenzintervall:
Irrtumsw. 1%
Irrtumsw. 5%
Irrtumsw. 10%
Konfidenzintervall 90%
6.808
273
69
Konfidenzintervall 95%
9.603
385
97
Konfidenzintervall 99%
16.637
666
167
Grundsätzlich gilt: Je höher das Konfidenzintervall und je geringer die Irrtumswahrscheinlichkeit, desto höher wird die Repräsentativität deiner Recherche ausfallen. Eine höchstmögliche Repräsentativität bedeutet aber auch, dass deine Échantillon entsprechend groß ausfallen muss.
Für unser Forschungsbeispiel bedeutet es zusammenfassend, dass mit einer Échantillon von 385 Befragten (bei einer Population bzw. der Population totale von 64.000.000 Personnes) die erzielten Ergebnisse aus unserer Sondage mit 95-prozentiger Sicherheit auf die untersuchte Population übertragbar sind. Darüber hinaus können wir angeben, dass selbst wenn man alle Personnes aus der Population totale befragen könnte, würden ihre Antworten maximal um +/-5 Prozent von denen aus unserer Sondage abweichen.
Hinweis: Unsere Darstellung der Stichprobenberechnung ist als eine vereinfachte Einführung in dieses Thema zu verstehen. Ausführliche statistische Darstellungen, um verschiedene Wahrscheinlichkeiten und Kennwerte zu berechnen, können wir in einem kurzen Beitrag unmöglich berücksichtigen. In den gängigen Statistik-Lehrbüchern werden die von uns angerissene Begriffe mit Sicherheit umfassender dargestellt.
Unser Literaturtipp: Quatember, Andreas (2019). Datenqualität in Stichprobenerhebungen. Eine verständnisorientierte Einführung in die Survey-Statistik. 3. édition. Berlin: Springer Spektrum.
➔ Dieses Band ist unsere Empfehlung für alle, die sich mit der Stichprobenberechnung beschäftigen und nach einem gut verständlichen praxisorientierten Lehrbuch suchen.

Das Problem mit der Repräsentativität in der Praxis
Ob in den wissenschaftlichen Studien oder bei einer BILD-Sondage: Die Repräsentativität wird in Zusammenhang mit verschiedenen Sondages gern und häufig benutzt. Vor allem in den Massenmedien werden solche Studien angepriesen, die mit dem Siegel “repräsentativ” werben.
Dabei gibt es in der modernen Forschungspraxis immer mehr Stimmen, die diesen Begriff in verschiedenen Aufsätzen kritisch betrachten. Schließlich gibt es in der Wissenschaft bisher keine allgemeingültige klare Definition der Repräsentativität.
Das Problem steckt hier im Detail: Wie definiert man überhaupt die Population totale? In unserem Forschungsbeispiel könnte man die Logik der Population totale ebenfalls hinterfragen: Zählen alle Menschen, die einen Fernseher besitzen, wirklich auch als Fernsehzuschauer? Gilt jede Personne aus einem Mehrfamilienhaushalt mit nur einem Fernsehgerät als Zuschauer?
Ebenfalls ist die Ziehung einer repräsentativen Zufallsstichprobe deutlich komplexer als in vielen Lehrbüchern dargestellt. Wie kann überhaupt bei einer Studie garantiert werden, dass jedes Element der Population totale die gleiche Chance hat, gezogen zu werden? Gerade den Online-Sondages wird vorgeworfen, dass im Internet nicht jede Bevölkerungsgruppe vertreten ist. Dabei gilt dieser Vorwurf grundsätzlich für jede anderen Methode: Oder wer ist schon heutzutage über einen Festnetzanschluss für eine telefonische Enquête erreichbar?
Für deine studentische Ausarbeitung bedeutet dies vor allem, dass die Repräsentativität weder in Stein gemeißelt ist, noch ist sie immer notwendig oder realisierbar. Zudem ist die Repräsentativität nicht das einzige Gütekriterium deiner Recherche: Was bringt dir eine repräsentative Sondage, wenn deine Fragen unverständlich formuliert sind?
Vielmehr solltest du in deiner Mémoire de fin d'études stets offenlegen, welche Schritte du bei dem gesamten Forschungsprojekt unternommen hast, um möglichst aussagekräftige Erkenntnisse in Bezug auf deine Question de recherche zu erhalten!

Die Wahl der Échantillon in die Mémoire de fin d'études integrieren
Beim Verfassen einer Mémoire de fin d'études kommst du an der Bildung einer geeigneten Échantillon unmittelbar nach der Wahl deiner Forschungsmethode nicht vorbei. Ob deine Échantillon nun repräsentativ sein wird – oder auch nicht, steht bei einer studentischen Arbeit dabei gar nicht im Vordergrund. Stattdessen wird von dir erwartet, dass du dir frühzeitig Gedanken über die untersuchte Bevölkerungsgruppe machst, mit der du deine Question de recherche bestmöglich erfassen kannst:
1. Einleitung: Question de recherche
2. Theorie: Stand der Recherche
3. Forschungsdesign
3.1 Bildung der Hypothesen
3.2. Wahl der Forschungsmethode, z.B. quantitative Enquête
→ 3.3. Échantillon festlegen
3.4. Definition und Festlegung der untersuchten Variablen und Merkmale
3.5. Fragenkatalog
4. Collecte de données
5. Datenauswertung
6. Ergebnisse und Erkenntnisse
7. Reflektion der eigenen Vorgehensweise
8. Fazit
Weiterführende Literatur:
Balzert, Helmut et al. (2011). Travail scientifique Arbeiten. 2 édition. Berlin/Dortmund: Springer Campus.
Beller, Sieghard (2016). Empirisch forschen lernen. Konzepte, Methoden, Fallbeispiele, Tipps. 2 édition. Bern: Huber Verlag.
Brosius, Hans-Bernd et al. (2009). Methoden der empirique Kommunikationsforschung. Eine Einführung. 5 édition. Wiesbaden: VS Verlag für Sciences sociales.
Holland, Heinrich/Kurt Scharnbacher (2004). Grundlagen statistischer Wahrscheinlichkeiten. Kombinationen, Wahrscheinlichkeiten, Binomial- und Normalverteilung, Konfidenzintervalle, Hypothesentests. Wiesbaden: Gabler Verlag.
Raithel, Jürgen (2008). quantitative Recherche. Ein Praxiskurs. 2. édition. Wiesbaden: VS Verlag für Sciences sociales.
Kromrey, Helmut (2002). empirique Sozialforschung: Modelle und Methoden der standardisierten Collecte de données und Datenauswertung. 10. édition. Opladen: Leske + Budrich.
Quatember, Andreas (2019). Datenqualität in Stichprobenerhebungen. Eine verständnisorientierte Einführung in die Survey-Statistik. 3. édition. Berlin: Springer Spektrum.
Folgende Chapitre könnten dich ebenfalls interessieren:
- Chapitre: Aufbau wissenschaftliche Arbeit: Bachelor- und Masterarbeit
- Chapitre: empirique Recherche in Abschlussarbeiten: Ablauf, Tipps und Beispiel
- Startseite empirioWissen: Finde das passende Chapitre für deine Frage
Créer un sondage gratuitement
Avec empirio.ai, vous créez un sondage en ligne moderne en quelques minutes — protection des données à 100 % depuis l'Allemagne.
Commencer gratuitement